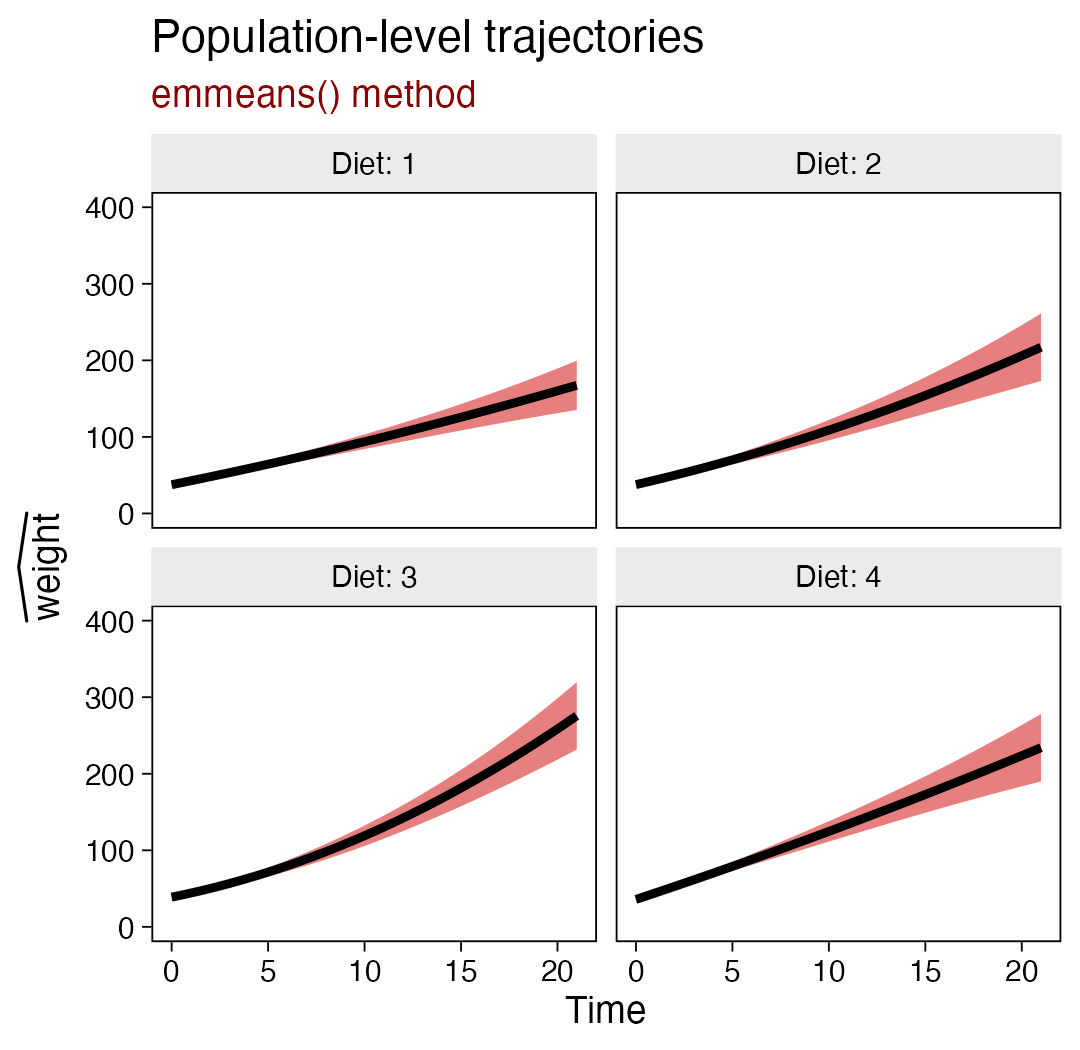
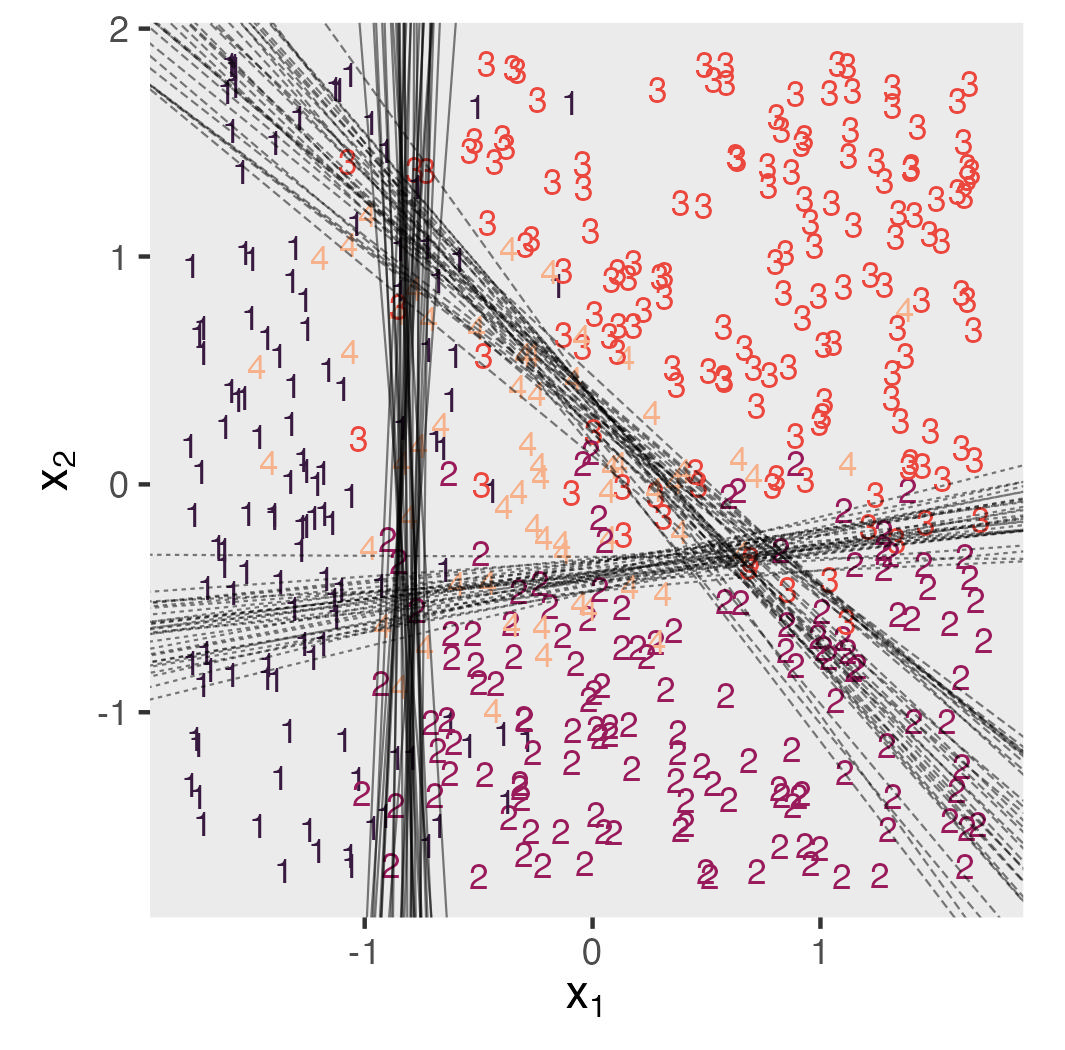
Learn Stan with brms, Part III
In this third post we explore different ways to fit a model with a mean-centered predictor, what this means for how we set our priors with brms, and what this all means for the underlying Stan code. Along the way we practice with the transformed data block, and get fancy with the model matrix.