Conditional logistic models with brms: Rough draft.
By A. Solomon Kurz
November 17, 2021
Version 1.1.0
Edited on December 12, 2022, to use the new as_draws_df() workflow.
Preamble
After tremendous help from Henrik Singmann and Mattan Ben-Shachar, I finally have two (!) workflows for conditional logistic models with brms. These workflows are on track to make it into the next update of my ebook translation of Kruschke’s text (see here). But these models are new to me and I’m not entirely confident I’ve walked them out properly.
The goal of this blog post is to present a draft of my workflow, which will eventually make it’s way into Chapter 22 of the ebook. If you have any constrictive criticisms, please pass them along on
- GitHub,
- this thread in the Stan forums,
- or on twitter.
To streamline this post a little, I have removed the content on the softmax model. For that material, just go to the ebook proper.
# in the ebook, this code will have already been executed
library(tidyverse)
library(brms)
library(tidybayes)
library(patchwork)
theme_set(
theme_gray() +
theme(panel.grid = element_blank())
)
Nominal Predicted Variable
This chapter considers data structures that have a nominal predicted variable. When the nominal predicted variable has only two possible values, this reduces to the case of the dichotomous predicted variable considered in the previous chapter. In the present chapter, we generalize to cases in which the predicted variable has three or more categorical values…
The traditional treatment of this sort of data structure is called multinomial logistic regression or conditional logistic regression. We will consider Bayesian approaches to these methods. As usual, in Bayesian software it is easy to generalize the traditional models so they are robust to outliers, allow different variances within levels of a nominal predictor, and have hierarchical structure to share information across levels or factors as appropriate. ( Kruschke, 2015, p. 649)
Softmax regression
Softmax reduces to logistic for two outcomes.
Independence from irrelevant attributes.
Conditional logistic regression
Softmax regression conceives of each outcome as an independent change in log odds from the reference outcome, and a special case of that is dichotomous logistic regression. But we can generalize logistic regression another way, which may better capture some patterns of data. The idea of this generalization is that we divide the set of outcomes into a hierarchy of two-set divisions, and use a logistic to describe the probability of each branch of the two-set divisions. (p. 655)
The model follows the generic equation
$$
\begin{align*} \phi_{S^* | S} = \operatorname{logistic}(\lambda_{S^* | S}) \\ \lambda_{S^* | S} = \beta_{0, S^* | S} + \beta_{1, {S^* | S}} x, \end{align*}
$$
where the conditional response probability (i.e., the goal of the analysis) is \(\phi_{S^* | S}\). \(S^*\) and \(S\) denote the subset of outcomes and larger set of outcomes, respectively, and \(\lambda_{S^* | S}\) is the propensity based on some linear model. The overall point is these “regression coefficients refer to the conditional probability of outcomes for the designated subsets, not necessarily to a single outcome among the full set of outcomes” (p. 655).
In Figure 22.2 (p. 656), Kruschke depicted the two hierarchies of binary divisions of the models he fit to the data in his CondLogistRegData1.csv and CondLogistRegData2.csv files. Here we load those data, save them as d3 and d4, and take a look at their structures.
d3 <- read_csv("data.R/CondLogistRegData1.csv")
d4 <- read_csv("data.R/CondLogistRegData2.csv")
glimpse(d3)
## Rows: 475
## Columns: 3
## $ X1 <dbl> -0.08714736, -0.72256565, 0.17918961, -1.15975176, -0.72711762, 0.5…
## $ X2 <dbl> -1.08134218, -1.58386308, 0.97179045, 0.50262438, 1.37570446, 1.774…
## $ Y <dbl> 2, 1, 3, 1, 3, 3, 2, 3, 2, 4, 1, 2, 2, 3, 4, 2, 2, 4, 2, 3, 4, 2, 1…
glimpse(d4)
## Rows: 475
## Columns: 3
## $ X1 <dbl> -0.08714736, -0.72256565, 0.17918961, -1.15975176, -0.72711762, 0.5…
## $ X2 <dbl> -1.08134218, -1.58386308, 0.97179045, 0.50262438, 1.37570446, 1.774…
## $ Y <dbl> 4, 4, 3, 4, 2, 3, 4, 3, 4, 4, 2, 4, 4, 3, 3, 4, 4, 4, 4, 3, 4, 4, 1…
In both data sets, the nominal criterion is Y and the two predictors are X1 and X2. Though the data seem simple, the conditional logistic models are complex enough that it seems like we’ll be better served by focusing on them one at a time, which means I’m going to break up Figure 22.2. Here’s how to make the diagram in the left panel.
# the big numbers
numbers <- tibble(
x = c(3, 5, 2, 4, 1, 3, 2),
y = c(0, 0, 1, 1, 2, 2, 3),
label = c("3", "4", "2", "3,4", "1", "2,3,4", "1,2,3,4")
)
# the smaller Greek numbers
greek <- tibble(
x = c(3.4, 4.6, 2.4, 3.6, 1.4, 2.6),
y = c(0.5, 0.5, 1.5, 1.5, 2.5, 2.5),
hjust = c(1, 0, 1, 0, 1, 0),
label = c("phi['{3}|{3,4}']", "1-phi['{3}|{3,4}']",
"phi['{2}|{2,3,4}']", "1-phi['{2}|{2,3,4}']",
"phi['{1}|{1,2,3,4}']", "1-phi['{1}|{1,2,3,4}']")
)
# arrows
tibble(
x = c(4, 4, 3, 3, 2, 2),
y = c(0.85, 0.85, 1.85, 1.85, 2.85, 2.85),
xend = c(3, 5, 2, 4, 1, 3),
yend = c(0.15, 0.15, 1.15, 1.15, 2.15, 2.15)
) %>%
# plot!
ggplot(aes(x = x, y = y)) +
geom_segment(aes(xend = xend, yend = yend),
linewidth = 1/4,
arrow = arrow(length = unit(0.08, "in"), type = "closed")) +
geom_text(data = numbers,
aes(label = label),
size = 5, family = "Times")+
geom_text(data = greek,
aes(label = label, hjust = hjust),
size = 4.25, family = "Times", parse = T) +
xlim(-1, 7) +
theme_void()
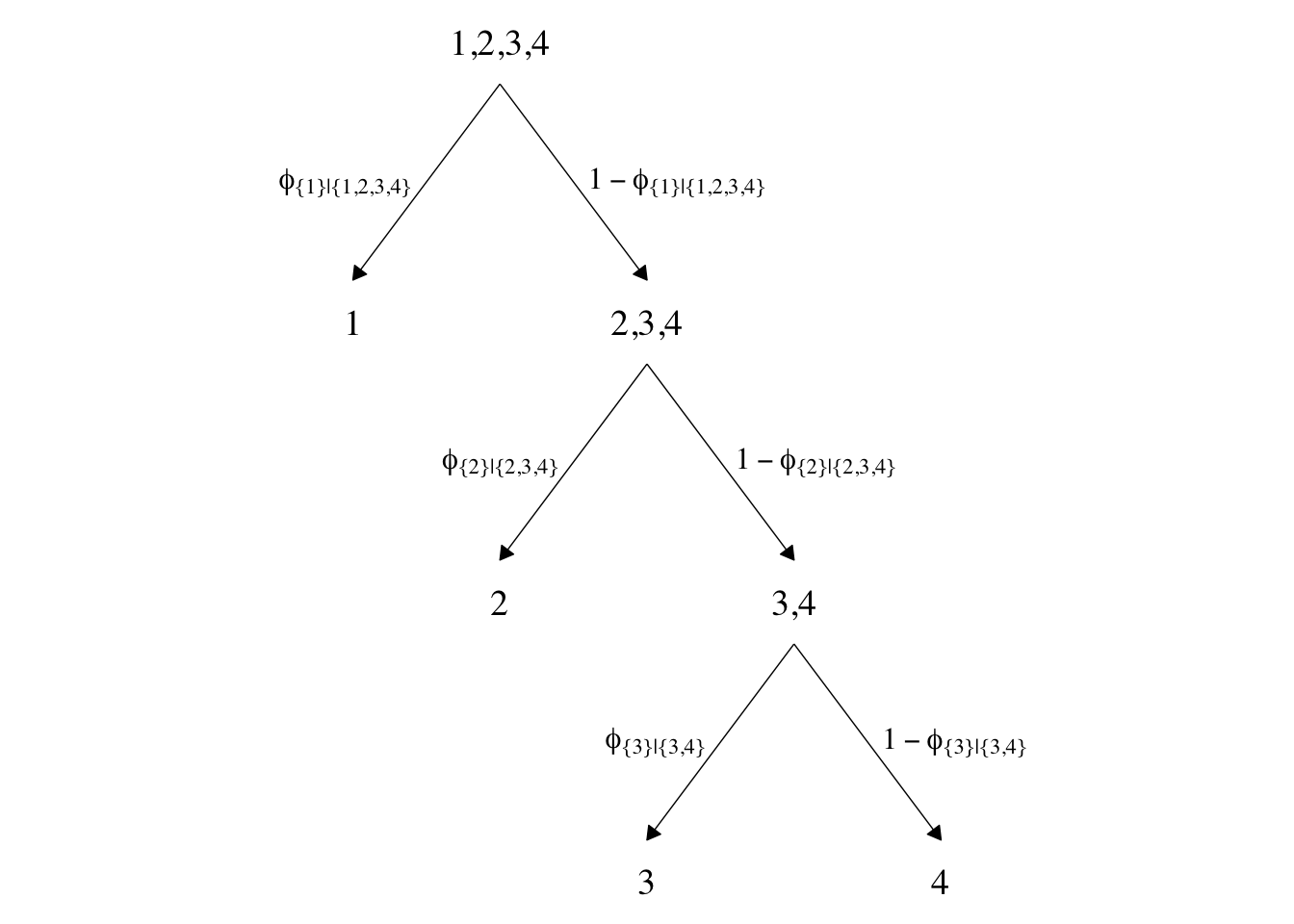
The large numbers are the four levels in the criterion Y and the smaller numbers in the curly braces are various sets of those numbers. The diagram shows three levels of outcome-set divisions:
- 1 versus 2, 3, or 4;
- 2 versus 3 or 4; and
- 3 versus 4.
The divisions in each of these levels can be expressed as linear models which we’ll denote \(\lambda\). Given our data with two predictors X1 and X2, we can express the three linear models as
$$
\begin{align*} \lambda_{\{ 1 \} | \{ 1,2,3,4 \}} & = \beta_{0,\{ 1 \} | \{ 1,2,3,4 \}} + \beta_{1,\{ 1 \} | \{ 1,2,3,4 \}} \text{X1} + \beta_{2,\{ 1 \} | \{ 1,2,3,4 \}} \text{X2} \\ \lambda_{\{ 2 \} | \{ 2,3,4 \}} & = \beta_{0,\{ 2 \} | \{ 2,3,4 \}} + \beta_{1,\{ 2 \} | \{ 2,3,4 \}} \text{X1} + \beta_{2,\{ 2 \} | \{ 2,3,4 \}} \text{X2} \\ \lambda_{\{ 3 \} | \{ 3,4 \}} & = \beta_{0,\{ 3 \} | \{ 3,4 \}} + \beta_{1,\{ 3 \} | \{ 3,4 \}} \text{X1} + \beta_{2,\{ 3 \} | \{ 3,4 \}} \text{X2}, \end{align*}
$$
where, for convenience, we’re omitting the typical \(i\) subscripts. As these linear models are all defined within the context of the logit link, we can express the conditional probabilities of the outcome sets as
$$
\begin{align*} \phi_{\{ 1 \} | \{ 1,2,3,4 \}} & = \operatorname{logistic} \left (\lambda_{\{ 1 \} | \{ 1,2,3,4 \}} \right) \\ \phi_{\{ 2 \} | \{ 2,3,4 \}} & = \operatorname{logistic} \left (\lambda_{\{ 2 \} | \{ 2,3,4 \}} \right) \\ \phi_{\{ 3 \} | \{ 3,4 \}} & = \operatorname{logistic} \left (\lambda_{\{ 3 \} | \{ 3,4 \}} \right), \end{align*}
$$
where \(\phi_{\{ 1 \} | \{ 1,2,3,4 \}}\) through \(\phi_{\{ 3 \} | \{ 3,4 \}}\) are the conditional probabilities for the outcome sets. If, however, we want the conditional probabilities for the actual levels of the criterion Y, we define those with a series of (in this case) four equations:
$$
\begin{align*} \phi_1 & = \phi_{\{ 1 \} | \{ 1,2,3,4 \}} \\ \phi_2 & = \phi_{\{ 2 \} | \{ 2,3,4 \}} \cdot \left ( 1 - \phi_{\{ 1 \} | \{ 1,2,3,4 \}} \right) \\ \phi_3 & = \phi_{\{ 3 \} | \{ 3,4 \}} \cdot \left ( 1 - \phi_{\{ 2 \} | \{ 2,3,4 \}} \right) \cdot \left ( 1 - \phi_{\{ 1 \} | \{ 1,2,3,4 \}} \right) \\ \phi_4 & = \left ( 1 - \phi_{\{ 3 \} | \{ 3,4 \}} \right) \cdot \left ( 1 - \phi_{\{ 2 \} | \{ 2,3,4 \}} \right) \cdot \left ( 1 - \phi_{\{ 1 \} | \{ 1,2,3,4 \}} \right), \end{align*}
$$
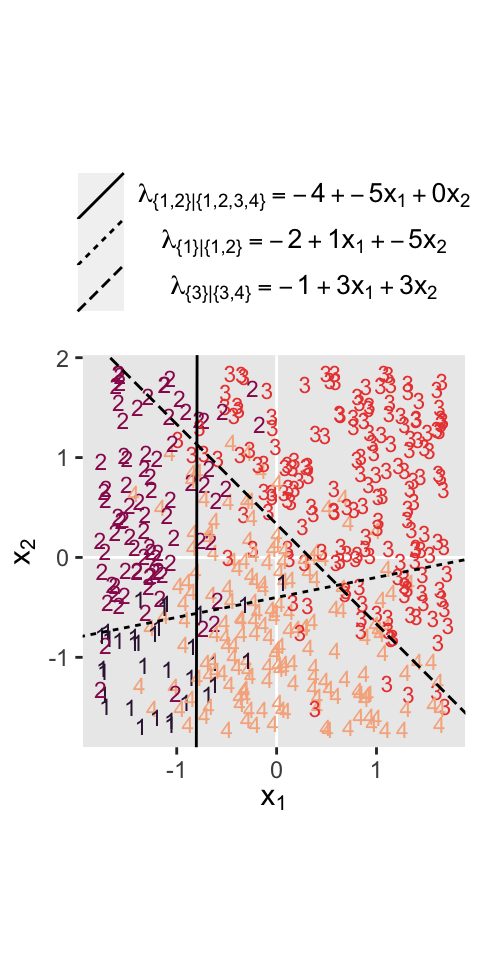
where the sum of the probabilities \(\phi_1\) through \(\phi_4\) is \(1\). To get a sense of what this all means in practice, let’s visualize the data and the data-generating equations for our version of Figure 22.3. As with the previous figure, I’m going to break this figure up to focus on one model at a time. Thus, here’s the left panel of Figure 22.3.
# define the various population parameters
# lambda 1
b01 <- -4
b11 <- -5
b21 <- 0.01 # rounding up to avoid dividing by zero
# lambda 2
b02 <- -2
b12 <- 1
b22 <- -5
# lambda 3
b03 <- -1
b13 <- 3
b23 <- 3
# use the parameters to define the lines
lines <- tibble(
intercept = c(-b01 / b21, -b02 / b22, -b03 / b23),
slope = c(-b11 / b21, -b12 / b22, -b13 / b23),
label = c("1", "2","3")
)
# wrangle
d3 %>%
mutate(Y = factor(Y)) %>%
# plot!
ggplot() +
geom_hline(yintercept = 0, color = "white") +
geom_vline(xintercept = 0, color = "white") +
geom_text(aes(x = X1, y = X2, label = Y, color = Y),
size = 3, show.legend = F) +
geom_abline(data = lines,
aes(intercept = intercept,
slope = slope,
linetype = label)) +
scale_color_viridis_d(option = "F", begin = .15, end = .85) +
scale_linetype(NULL,
labels = parse(text = c(
"lambda['{1}|{1,2,3,4}']==-4+-5*x[1]+0*x[2]",
"lambda['{2}|{2,3,4}']==-2+1*x[1]+-5*x[2]",
"lambda['{3}|{3,4}']==-1+3*x[1]+3*x[2]")),
guide = guide_legend(
direction = "vertical",
label.hjust = 0.5,
label.theme = element_text(size = 10))) +
coord_equal() +
labs(x = expression(x[1]),
y = expression(x[2])) +
theme(legend.justification = 0.5,
legend.position = "top")
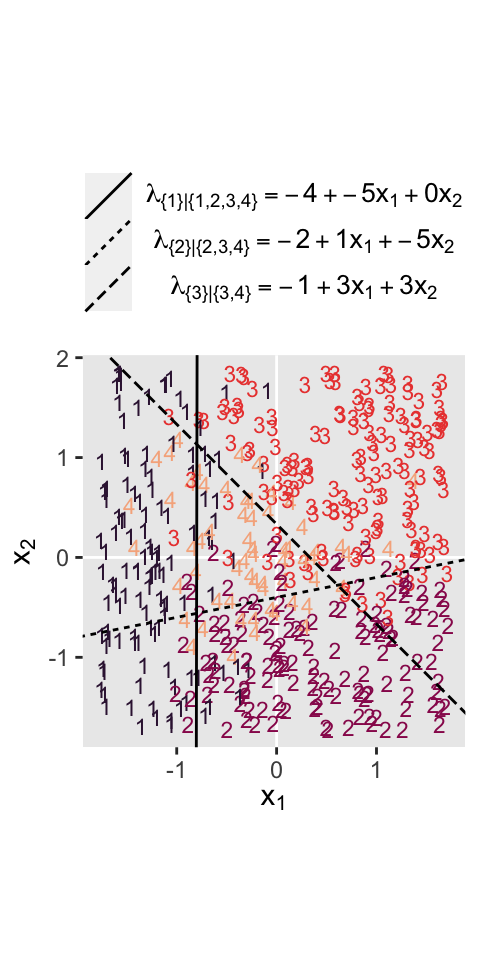
Recall back on page 629, Kruschke showed the equation for the 50% threshold of a logistic regression model given two continuous predictors was
$$x_2 = (-\beta_0 / \beta_2) + (-\beta_1 / \beta_2) x_1.$$
It was that equation that gave us the values for the intercept and slope arguments ($-\beta_0 / \beta_2$ and \(-\beta_1 / \beta_2\), respectively) for the geom_abline() function.
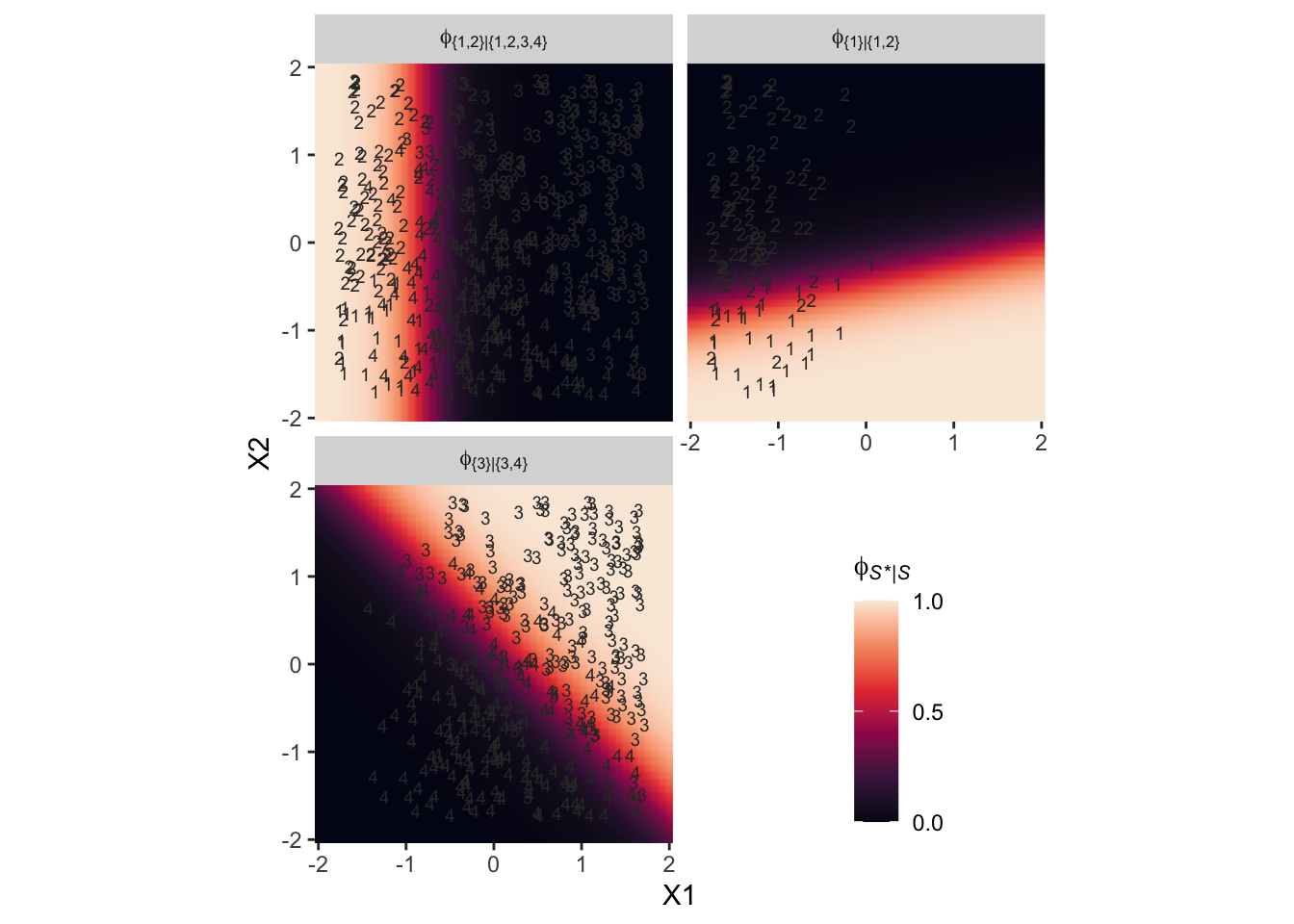
It still might not be clear how the various \(\phi_{S^* | S}\) values connect to the data. Though not in the text, here’s an alternative way of expressing the relations in Figure 22.3. This time the plot is faceted by the three levels of \(\phi_{S^* | S}\) and the background fill is based on those conditional probabilities.
# define a grid of X1 and X2 values
crossing(X1 = seq(from = -2, to = 2, length.out = 50),
X2 = seq(from = -2, to = 2, length.out = 50)) %>%
# compute the lambda's
mutate(`lambda['{1}|{1,2,3,4}']` = b01 + b11 * X1 + b21 * X2,
`lambda['{2}|{2,3,4}']` = b02 + b12 * X1 + b22 * X2,
`lambda['{3}|{3,4}']` = b03 + b13 * X1 + b23 * X2) %>%
# compute the phi's
mutate(`phi['{1}|{1,2,3,4}']` = plogis(`lambda['{1}|{1,2,3,4}']`),
`phi['{2}|{2,3,4}']` = plogis(`lambda['{2}|{2,3,4}']`),
`phi['{3}|{3,4}']` = plogis(`lambda['{3}|{3,4}']`)) %>%
# wrangle
pivot_longer(contains("phi"), values_to = "phi") %>%
# plot!
ggplot(aes(x = X1, y = X2)) +
geom_raster(aes(fill = phi),
interpolate = T) +
# note how we're subsetting the d3 data by facet
geom_text(data = bind_rows(
d3 %>% mutate(name = "phi['{1}|{1,2,3,4}']"),
d3 %>% mutate(name = "phi['{2}|{2,3,4}']") %>% filter(Y > 1),
d3 %>% mutate(name = "phi['{3}|{3,4}']") %>% filter(Y > 2)),
aes(label = Y),
size = 2.5, color = "grey20") +
scale_fill_viridis_c(expression(phi[italic(S)*"*|"*italic(S)]),
option = "F", breaks = 0:2 / 2, limits = c(0, 1)) +
scale_x_continuous(expand = c(0, 0)) +
scale_y_continuous(expand = c(0, 0)) +
coord_equal() +
theme(legend.position = c(0.8, 0.2)) +
facet_wrap(~ name, labeller = label_parsed, ncol = 2)
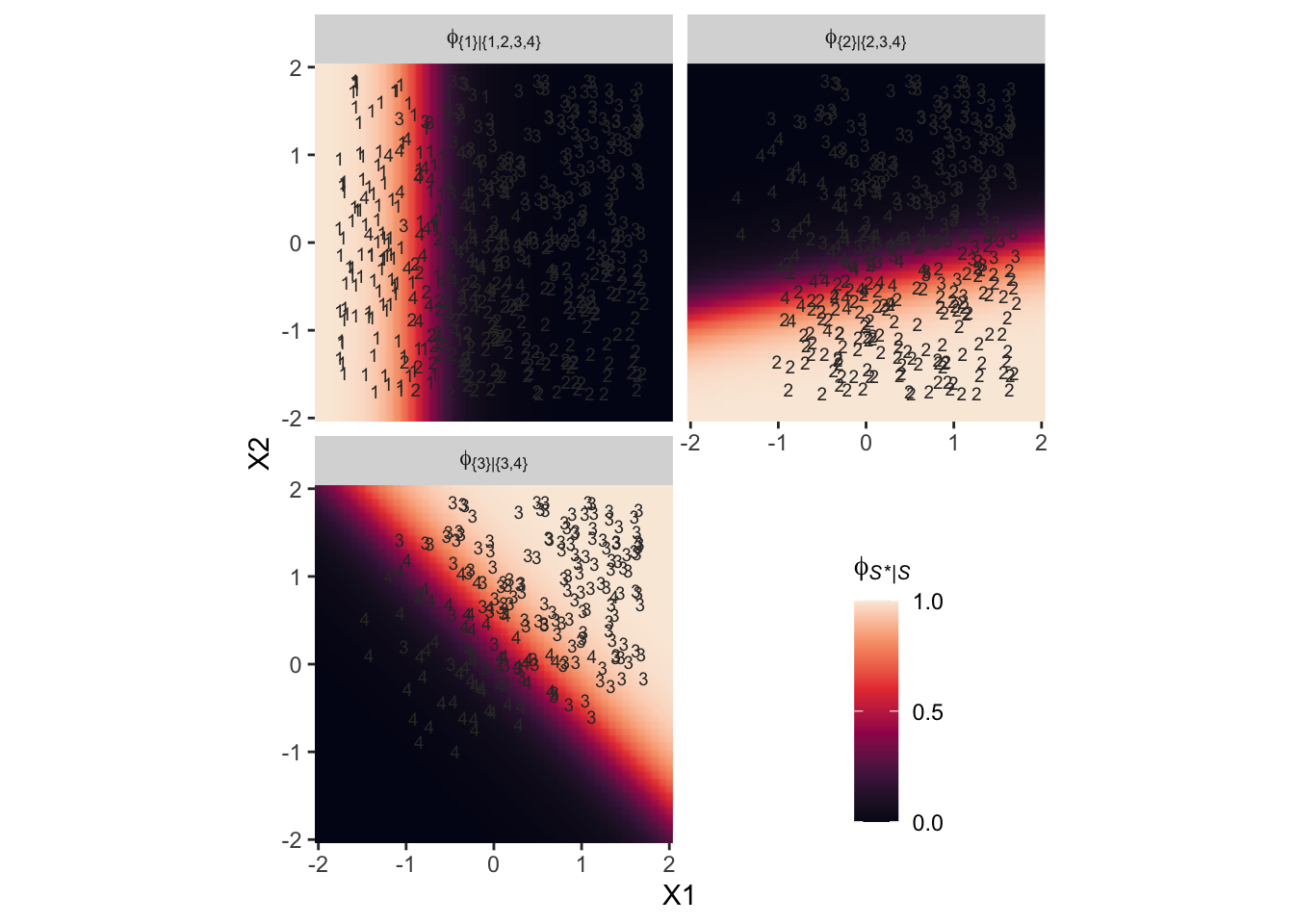
Notice how because each of the levels of \(\phi\) is defined by a different subset of the data, each of the facets contains a different subset of the d3 data, too. For example, since \(\phi_{\{ 1 \} | \{ 1,2,3,4 \}}\) is defined by the full subset of the possible values of Y, you see all the Y data displayed by geom_text() for that facet. In contrast, since \(\phi_{\{ 3 \} | \{ 3,4 \}}\) is defined by a subset of the data for which Y is only 3 or 4, those are the only values you see displayed within that facet of the plot.
Now we’ll consider an alternative way to set up the binary-choices hierarchy, as seen in the right panel of Figure 22.2. First, here’s that half of the figure.
# the big numbers
numbers <- tibble(
x = c(0, 2, 6, 8, 1, 7, 4),
y = c(0, 0, 0, 0, 1, 1, 2),
label = c("1", "2", "3", "4", "1,2", "3,4", "1,2,3,4")
)
# the smaller Greek numbers
greek <- tibble(
x = c(0.4, 1.6, 6.4, 7.6, 2.1, 5.8),
y = c(0.5, 0.5, 0.5, 0.5, 1.5, 1.5),
hjust = c(1, 0, 1, 0, 1, 0),
label = c("phi['{1}|{1,2}']", "1-phi['{1}|{1,2}']",
"phi['{3}|{3,4}']", "1-phi['{3}|{3,4}']",
"phi['{1,2}|{1,2,3,4}']", "1-phi['{1,2}|{1,2,3,4}']")
)
# arrows
tibble(
x = c(1, 1, 7, 7, 4, 4),
y = c(0.85, 0.85, 0.85, 0.85, 1.85, 1.85),
xend = c(0, 2, 6, 8, 1, 7),
yend = c(0.15, 0.15, 0.15, 0.15, 1.15, 1.15)
) %>%
# plot!
ggplot(aes(x = x, y = y)) +
geom_segment(aes(xend = xend, yend = yend),
linewidth = 1/4,
arrow = arrow(length = unit(0.08, "in"), type = "closed")) +
geom_text(data = numbers,
aes(label = label),
size = 5, family = "Times")+
geom_text(data = greek,
aes(label = label, hjust = hjust),
size = 4.25, family = "Times", parse = T) +
xlim(-1, 10) +
theme_void()
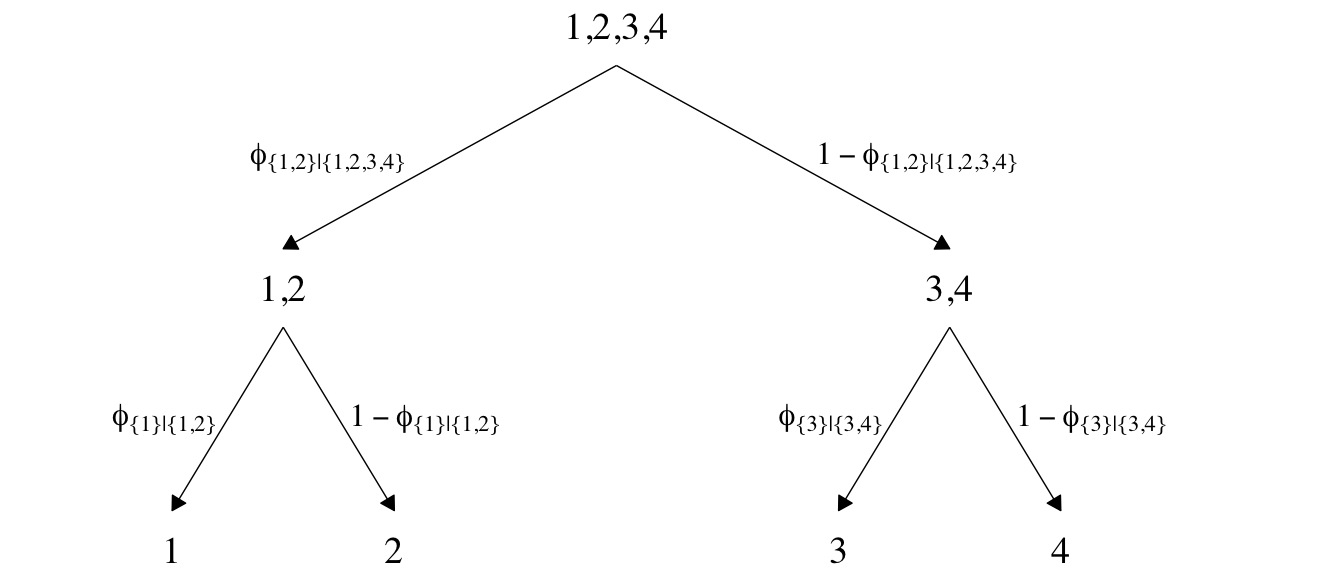
This diagram shows three levels of outcome-set divisions:
- 1 or 2 versus 3 or 4;
- 1 versus 2; and
- 3 versus 4.
Given our data with two predictors X1 and X2, we can express the three linear models as
$$
\begin{align*} \lambda_{\{ 1,2 \} | \{ 1,2,3,4 \}} & = \beta_{0,\{ 1,2 \} | \{ 1,2,3,4 \}} + \beta_{1,\{ 1,2 \} | \{ 1,2,3,4 \}} \text{X1} + \beta_{2,\{ 1,2 \} | \{ 1,2,3,4 \}} \text{X2} \\ \lambda_{\{ 1 \} | \{ 1,2 \}} & = \beta_{0,\{ 1 \} | \{ 1,2 \}} + \beta_{1,\{ 1 \} | \{ 1,2 \}} \text{X1} + \beta_{2,\{ 1 \} | \{ 1,2 \}} \text{X2} \\ \lambda_{\{ 3 \} | \{ 3,4 \}} & = \beta_{0,\{ 3 \} | \{ 3,4 \}} + \beta_{1,\{ 3 \} | \{ 3,4 \}} \text{X1} + \beta_{2,\{ 3 \} | \{ 3,4 \}} \text{X2}. \end{align*}
$$
We can then express the conditional probabilities of the outcome sets as
$$
\begin{align*} \phi_{\{ 1,2 \} | \{ 1,2,3,4 \}} & = \operatorname{logistic} \left (\lambda_{\{ 1,2 \} | \{ 1,2,3,4 \}} \right) \\ \phi_{\{ 1 \} | \{ 1,2 \}} & = \operatorname{logistic} \left (\lambda_{\{ 1 \} | \{ 1,2 \}} \right) \\ \phi_{\{ 3 \} | \{ 3,4 \}} & = \operatorname{logistic} \left (\lambda_{\{ 3 \} | \{ 3,4 \}} \right). \end{align*}
$$
For the conditional probabilities of the actual levels of the criterion Y, we define those with a series of (in this case) four equations:
$$
\begin{align*} \phi_1 & = \phi_{\{ 1 \} | \{ 1,2 \}} \cdot \phi_{\{ 1,2 \} | \{ 1,2,3,4 \}} \\ \phi_2 & = \left ( 1 - \phi_{\{ 1 \} | \{ 1,2 \}} \right) \cdot \phi_{\{ 1,2 \} | \{ 1,2,3,4 \}} \\ \phi_3 & = \phi_{\{ 3 \} | \{ 3,4 \}} \cdot \left ( 1 - \phi_{\{ 1,2 \} | \{ 1,2,3,4 \}} \right) \\ \phi_4 & = \left ( 1 - \phi_{\{ 3 \} | \{ 3,4 \}} \right) \cdot \left ( 1 - \phi_{\{ 1,2 \} | \{ 1,2,3,4 \}} \right), \end{align*}
$$
where the sum of the probabilities \(\phi_1\) through \(\phi_4\) is \(1\). To get a sense of what this all means, let’s visualize the data and the data-generating equations in our version of the right panel of Figure 22.3.
d4 %>%
mutate(Y = factor(Y)) %>%
ggplot() +
geom_hline(yintercept = 0, color = "white") +
geom_vline(xintercept = 0, color = "white") +
geom_text(aes(x = X1, y = X2, label = Y, color = Y),
size = 3, show.legend = F) +
geom_abline(data = lines,
aes(intercept = intercept,
slope = slope,
linetype = label)) +
scale_color_viridis_d(option = "F", begin = .15, end = .85) +
scale_linetype(NULL,
labels = parse(text = c(
"lambda['{1,2}|{1,2,3,4}']==-4+-5*x[1]+0*x[2]",
"lambda['{1}|{1,2}']==-2+1*x[1]+-5*x[2]",
"lambda['{3}|{3,4}']==-1+3*x[1]+3*x[2]")),
guide = guide_legend(
direction = "vertical",
label.hjust = 0.5,
label.theme = element_text(size = 10))) +
coord_equal() +
labs(x = expression(x[1]),
y = expression(x[2])) +
theme(legend.justification = 0.5,
legend.position = "top")
Here’s an alternative way of expression the relations in the right panel of Figure 22.3. This time the plot is faceted by the three levels of \(\phi_{S^* | S}\) and the background fill is based on those conditional probabilities.
# define a grid of X1 and X2 values
crossing(X1 = seq(from = -2, to = 2, length.out = 50),
X2 = seq(from = -2, to = 2, length.out = 50)) %>%
# compute the lambda's
mutate(`lambda['{1,2}|{1,2,3,4}']` = b01 + b11 * X1 + b21 * X2,
`lambda['{1}|{1,2}']` = b02 + b12 * X1 + b22 * X2,
`lambda['{3}|{3,4}']` = b03 + b13 * X1 + b23 * X2) %>%
# compute the phi's
mutate(`phi['{1,2}|{1,2,3,4}']` = plogis(`lambda['{1,2}|{1,2,3,4}']`),
`phi['{1}|{1,2}']` = plogis(`lambda['{1}|{1,2}']`),
`phi['{3}|{3,4}']` = plogis(`lambda['{3}|{3,4}']`)) %>%
# wrangle
pivot_longer(contains("phi"), values_to = "phi") %>%
# plot!
ggplot(aes(x = X1, y = X2)) +
geom_raster(aes(fill = phi),
interpolate = T) +
# note how we're subsetting the d3 data by facet
geom_text(data = bind_rows(
d4 %>% mutate(name = "phi['{1,2}|{1,2,3,4}']"),
d4 %>% mutate(name = "phi['{1}|{1,2}']") %>% filter(Y < 3),
d4 %>% mutate(name = "phi['{3}|{3,4}']") %>% filter(Y > 2)),
aes(label = Y),
size = 2.5, color = "grey20") +
scale_fill_viridis_c(expression(phi[italic(S)*"*|"*italic(S)]),
option = "F", breaks = 0:2 / 2, limits = c(0, 1)) +
scale_x_continuous(expand = c(0, 0)) +
scale_y_continuous(expand = c(0, 0)) +
coord_equal() +
theme(legend.position = c(0.8, 0.2)) +
facet_wrap(~ name, labeller = label_parsed, ncol = 2)
It could be easy to miss due to the way we broke up our workflow, but if you look closely at the \(\lambda\) equations at the top of both panels of Figure 22.3, you’ll see the right-hand side of the equations are the same. But because of the differences in the two data hierarchies, those \(\lambda\) equations had different consequences for how the X1 and X2 values generated the Y data. Also,
In general, conditional logistic regression requires that there is a linear division between two subsets of the outcomes, and then within each of those subsets there is a linear division of smaller subsets, and so on. This sort of linear division is not required of the softmax regression model… Real data can be extremely noisy, and there can be multiple predictors, so it can be challenging or impossible to visually ascertain which sort of model is most appropriate. The choice of model is driven primarily by theoretical meaningfulness. (p. 659)
Implementation in JAGS brms
Softmax model.
Conditional logistic model.
The conditional logistic regression models are not natively supported in brms at this time. Based on issue #560 in the brms GitHub, there are ways to fit them using the nonlinear syntax. If you compare the syntax Bürkner used in that thread on January 30th to the JAGS syntax Kruschke showed on pages 661 and 662, you’ll see they appear to follow contrasting parameterizations.
However, there are at least two other ways to fit conditional logistic models with brms. Based on insights from Henrik Singmann, we can define conditional logistic models using the custom family approach. In contrast, Mattan Ben-Shachar has shown we can also fit conditional logistic models using a tricky application of sequential ordinal regression. Rather than present them in the abstract, here, we will showcase both of these approaches in the sections below.
Results: Interpreting the regression coefficients.
Softmax model.
Bonus: Consider the interceps-only softmax model.
Conditional logistic model.
Since we will be fitting the conditional logistic model with two different strategies, I’m going to deviate from how Kruschke organized this part of the text and break this section up into two subsections:
- First we’ll walk through the custom family approach.
- Second we’ll explore the sequential ordinal approach.
Conditional logistic models with custom likelihoods.
As we briefly learned in [Section 8.6.1][Defining new likelihood functions.], brms users can define their own custom likelihood functions, which Bürkner outlined in his (
2021) vignette,
Define custom response distributions with brms. As part of the
Nominal data and Kruschke’s “conditional logistic” approach thread on the Stan forums, Henrik Singmann showed how you can use this functionality to fit conditional logistic models with brms. We will practice how to do this for the models of both the d3 and d4 data sets, which were showcased in the left and right panels of Figure 22.3 in
Section 22.2. Going in order, we’ll focus first on how to model the data in d3.
For the first step, we use the custom_family() function to
- name the new family with the
nameargument, - name the family’s parameters with the
dparsargument, - name the link function(s) with the
linksargument, - define whether the distribution is discrete or continuous with the
typeargument, - provide the names of any variables that are part of the internal workings of the family but are not among the distributional parameters with the
varsargument, and - provide supporting information with the
specialsargument.
cond_log_1 <- custom_family(
name = "cond_log_1",
dpars = c("mu", "mub", "muc"),
links = "identity",
type = "int",
vars = c("n_cat"),
specials = "categorical"
)
In the second step, we use the stanvar() function to define our custom probability mass function and the corresponding function that will allow us to return predictions.
stan_lpmf_1 <- stanvar(block = "functions",
scode = "
real cond_log_1_lpmf(int y, real mu, real mu_b, real mu_c, int n_cat) {
real p_mu = inv_logit(mu);
real p_mub = inv_logit(mu_b);
real p_muc = inv_logit(mu_c);
vector[n_cat] prob;
prob[1] = p_mu;
prob[2] = p_mub * (1 - p_mu);
prob[3] = p_muc * (1 - p_mub) * (1 - p_mu);
prob[4] = (1 - p_mu) * (1 - p_mub) * (1 - p_muc);
return(categorical_lpmf(y | prob));
}
vector cond_log_1_pred(int y, real mu, real mu_b, real mu_c, int n_cat) {
real p_mu = inv_logit(mu);
real p_mub = inv_logit(mu_b);
real p_muc = inv_logit(mu_c);
vector[n_cat] prob;
prob[1] = p_mu;
prob[2] = p_mub * (1 - p_mu);
prob[3] = p_muc * (1 - p_mub) * (1 - p_mu);
prob[4] = (1 - p_mu) * (1 - p_mub) * (1 - p_muc);
return(prob);
}
")
Note how we have defined the four prob[i] values based on the four equations from above:
$$
\begin{align*} \phi_1 & = \phi_{\{ 1 \} | \{ 1,2,3,4 \}} \\ \phi_2 & = \phi_{\{ 2 \} | \{ 2,3,4 \}} \cdot \left ( 1 - \phi_{\{ 1 \} | \{ 1,2,3,4 \}} \right) \\ \phi_3 & = \phi_{\{ 3 \} | \{ 3,4 \}} \cdot \left ( 1 - \phi_{\{ 2 \} | \{ 2,3,4 \}} \right) \cdot \left ( 1 - \phi_{\{ 1 \} | \{ 1,2,3,4 \}} \right) \\ \phi_4 & = \left ( 1 - \phi_{\{ 3 \} | \{ 3,4 \}} \right) \cdot \left ( 1 - \phi_{\{ 2 \} | \{ 2,3,4 \}} \right) \cdot \left ( 1 - \phi_{\{ 1 \} | \{ 1,2,3,4 \}} \right). \end{align*}
$$
Third, we save another stanvar() object with additional information.
stanvars <- stanvar(x = 4, name = "n_cat", scode = " int n_cat;")
Now we’re ready to fit the model with brm(). Notice how our use of the family and stanvars functions.
fit22.3 <-
brm(data = d3,
family = cond_log_1,
Y ~ 1 + X1 + X2,
prior = c(prior(normal(0, 20), class = Intercept, dpar = mu2),
prior(normal(0, 20), class = Intercept, dpar = mu3),
prior(normal(0, 20), class = Intercept, dpar = mu4),
prior(normal(0, 20), class = b, dpar = mu2),
prior(normal(0, 20), class = b, dpar = mu3),
prior(normal(0, 20), class = b, dpar = mu4)),
iter = 2000, warmup = 1000, cores = 4, chains = 4,
seed = 22,
stanvars = stan_lpmf_1 + stanvars,
file = "fits/fit22.03")
Check the model summary.
print(fit22.3)
## Family: cond_log_1
## Links: mu2 = identity; mu3 = identity; mu4 = identity
## Formula: Y ~ 1 + X1 + X2
## Data: d3 (Number of observations: 475)
## Draws: 4 chains, each with iter = 2000; warmup = 1000; thin = 1;
## total post-warmup draws = 4000
##
## Population-Level Effects:
## Estimate Est.Error l-95% CI u-95% CI Rhat Bulk_ESS Tail_ESS
## mu2_Intercept -4.02 0.47 -5.01 -3.17 1.00 3108 2656
## mu3_Intercept -2.13 0.36 -2.88 -1.50 1.00 2490 2211
## mu4_Intercept -0.96 0.32 -1.62 -0.38 1.00 3014 2674
## mu2_X1 -4.92 0.54 -6.03 -3.94 1.00 3029 2832
## mu2_X2 0.01 0.20 -0.37 0.40 1.00 4950 2436
## mu3_X1 0.74 0.30 0.16 1.35 1.00 3343 2736
## mu3_X2 -5.21 0.63 -6.54 -4.06 1.00 2748 2794
## mu4_X1 3.00 0.49 2.10 4.05 1.00 3002 2280
## mu4_X2 3.10 0.53 2.16 4.25 1.00 2646 2412
##
## Draws were sampled using sampling(NUTS). For each parameter, Bulk_ESS
## and Tail_ESS are effective sample size measures, and Rhat is the potential
## scale reduction factor on split chains (at convergence, Rhat = 1).
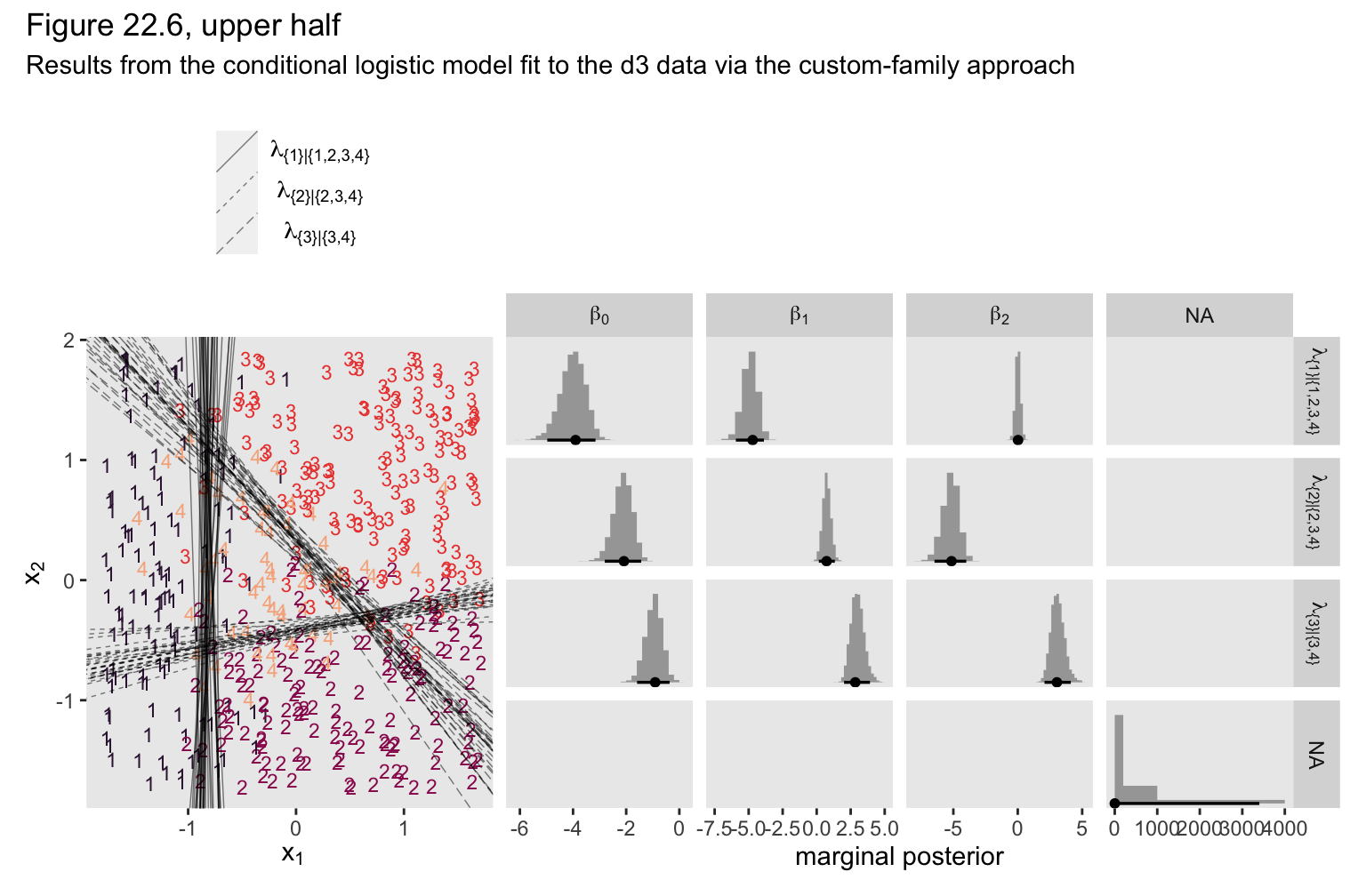
As they aren’t the most intuitive, here’s how to understand our three prefixes:
mu2_has to do with\(\lambda_{\{ 1 \} | \{ 1,2,3,4 \}}\),mu3_has to do with\(\lambda_{\{ 2 \} | \{ 2,3,4 \}}\), andmu4_has to do with\(\lambda_{\{ 3 \} | \{ 3,4 \}}\).
If you compare those posterior means of each of those parameters from the data-generating equations at the top of Figure 22.3, you’ll see they are spot on (within simulation variance). Here’s how we might visualize those posteriors in our version of the histograms in the top right panel(s) of Figure 22.6.
# extract the posterior draws
draws <- as_draws_df(fit22.3)
# wrangle
p1 <-
draws %>%
pivot_longer(-lp__) %>%
mutate(name = str_remove(name, "b_")) %>%
mutate(number = str_extract(name, "[2-4]+")) %>%
mutate(lambda = case_when(number == "2" ~ "lambda['{1}|{1,2,3,4}']",
number == "3" ~ "lambda['{2}|{2,3,4}']",
number == "4" ~ "lambda['{3}|{3,4}']"),
parameter = case_when(str_detect(name, "Intercept") ~ "beta[0]",
str_detect(name, "X1") ~ "beta[1]",
str_detect(name, "X2") ~ "beta[2]")) %>%
# plot
ggplot(aes(x = value, y = 0)) +
stat_histinterval(point_interval = mode_hdi, .width = .95, size = 1,
normalize = "panels") +
scale_y_continuous(NULL, breaks = NULL) +
xlab("marginal posterior") +
facet_grid(lambda ~ parameter, labeller = label_parsed, scales = "free_x")
If we use the threshold formula from above,
$$x_2 = (-\beta_0 / \beta_2) + (-\beta_1 / \beta_2)x_1,$$
to the posterior draws, we can make our version of the upper left panel of Figure 22.6.
set.seed(22)
p2 <-
draws %>%
mutate(draw = 1:n()) %>%
slice_sample(n = 30) %>%
pivot_longer(starts_with("b_")) %>%
mutate(name = str_remove(name, "b_mu")) %>%
separate(name, into = c("lambda", "parameter")) %>%
pivot_wider(names_from = parameter, values_from = value) %>%
mutate(intercept = -Intercept / X2,
slope = -X1 / X2) %>%
ggplot() +
geom_text(data = d3,
aes(x = X1, y = X2, label = Y, color = factor(Y)),
size = 3, show.legend = F) +
geom_abline(aes(intercept = intercept,
slope = slope,
group = interaction(draw, lambda),
linetype = lambda),
linewidth = 1/4, alpha = 1/2) +
scale_color_viridis_d(option = "F", begin = .15, end = .85) +
scale_linetype(NULL,
labels = parse(text = c(
"lambda['{1}|{1,2,3,4}']",
"lambda['{2}|{2,3,4}']",
"lambda['{3}|{3,4}']")),
guide = guide_legend(
direction = "vertical",
label.hjust = 0.5,
label.theme = element_text(size = 10))) +
labs(x = expression(x[1]),
y = expression(x[2])) +
theme(legend.justification = 0.5,
legend.position = "top")
Now combine the two ggplots, add a little formatting, and show the full upper half of Figure 22.6, based on the custom_family() approach.
(p2 + p1) &
plot_layout(widths = c(1, 2)) &
plot_annotation(title = "Figure 22.6, upper half",
subtitle = "Results from the conditional logistic model fit to the d3 data via the custom-family approach")
Though it isn’t necessary to reproduce any of the plots in this section of Kruschke’s text, we’ll want to use the expose_functions() function if we wanted to use any of the brms post-processing functions for our model fit with the custom likelihood.
expose_functions(fit22.3, vectorize = TRUE)
Here’s what we’d need to do before computing information criteria estimates, such as with the WAIC.
log_lik_cond_log_1 <- function(i, prep) {
mu <- brms::get_dpar(prep, "mu2", i = i)
mub <- brms::get_dpar(prep, "mu3", i = i)
muc <- brms::get_dpar(prep, "mu4", i = i)
n_cat <- prep$data$n_cat
y <- prep$data$Y[i]
cond_log_1_lpmf(y, mu, mub, muc, n_cat)
}
fit22.3 <- add_criterion(fit22.3, criterion = "waic")
waic(fit22.3)
##
## Computed from 4000 by 475 log-likelihood matrix
##
## Estimate SE
## elpd_waic -230.8 16.8
## p_waic 9.3 1.1
## waic 461.6 33.6
##
## 2 (0.4%) p_waic estimates greater than 0.4. We recommend trying loo instead.
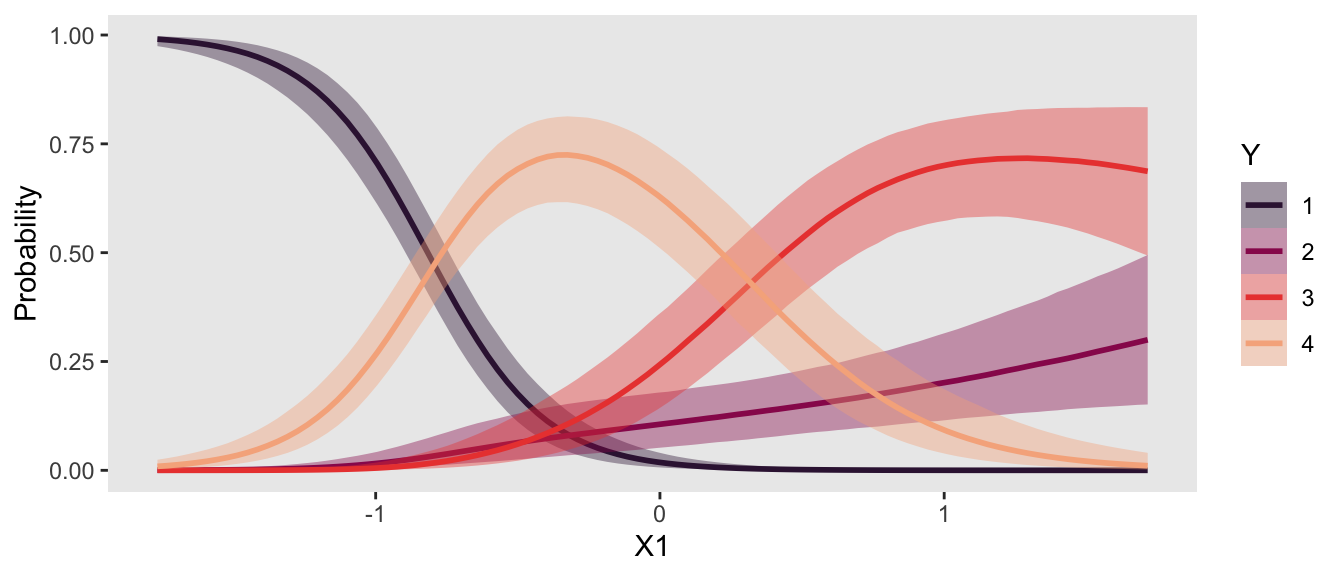
If we wanted to use one of the functions that relies on conditional expectations, such as conditional_effects(), we’d execute something like this.
posterior_epred_cond_log_1 <- function(prep) {
mu <- brms::get_dpar(prep, "mu2")
mu_b <- brms::get_dpar(prep, "mu3")
mu_c <- brms::get_dpar(prep, "mu4")
n_cat <- prep$data$n_cat
y <- prep$data$Y
prob <- cond_log_1_pred(y = y, mu = mu, mu_b = mu_b, mu_c = mu_c, n_cat = n_cat)
dim(prob) <- c(dim(prob)[1], dim(mu))
prob <- aperm(prob, c(2,3,1))
dimnames(prob) <- list(
as.character(seq_len(dim(prob)[1])),
NULL,
as.character(seq_len(dim(prob)[3]))
)
prob
}
ce <- conditional_effects(
fit22.3,
categorical = T,
effects = "X1")
plot(ce, plot = FALSE)[[1]] +
scale_fill_viridis_d(option = "F", begin = .15, end = .85) +
scale_color_viridis_d(option = "F", begin = .15, end = .85)
If we wanted to do a posterior predictive check with the pp_check() function, we’d need to do something like this.
posterior_predict_cond_log_1 <- function(i, prep, ...) {
mu <- brms::get_dpar(prep, "mu2", i = i)
mu_b <- brms::get_dpar(prep, "mu3", i = i)
mu_c <- brms::get_dpar(prep, "mu4", i = i)
n_cat <- prep$data$n_cat
y <- prep$data$Y[i]
prob <- cond_log_1_pred(y, mu, mu_b, mu_c, n_cat)
# make sure you have the extraDistr package
extraDistr::rcat(length(mu), t(prob))
}
pp_check(fit22.3,
type = "bars",
ndraws = 100,
size = 1/2,
fatten = 2)
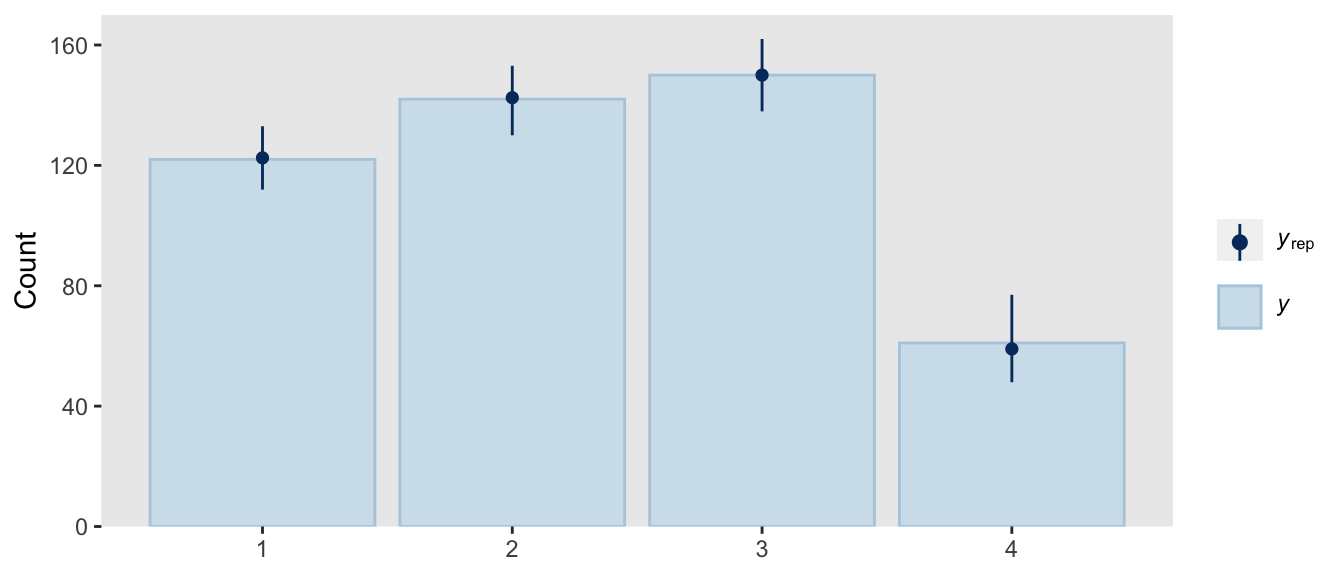
So far all of this has been with the conditional logistic model based on the first hierarchy of two-set divisions, which Kruschke used to simulate the d3 data. Now we’ll switch to consider the second hierarchy of two-set divisions, with which Kruschke simulated the d4 data. That second hierarchy, recall, resulted in the following definition for the conditional probabilities for the four levels of Y:
$$
\begin{align*} \phi_1 & = \phi_{\{ 1 \} | \{ 1,2 \}} \cdot \phi_{\{ 1,2 \} | \{ 1,2,3,4 \}} \\ \phi_2 & = \left ( 1 - \phi_{\{ 1 \} | \{ 1,2 \}} \right) \cdot \phi_{\{ 1,2 \} | \{ 1,2,3,4 \}} \\ \phi_3 & = \phi_{\{ 3 \} | \{ 3,4 \}} \cdot \left ( 1 - \phi_{\{ 1,2 \} | \{ 1,2,3,4 \}} \right) \\ \phi_4 & = \left ( 1 - \phi_{\{ 3 \} | \{ 3,4 \}} \right) \cdot \left ( 1 - \phi_{\{ 1,2 \} | \{ 1,2,3,4 \}} \right). \end{align*}
$$
This will require us to define a new custom family, which we’ll call cond_log_2.
cond_log_2 <- custom_family(
name = "cond_log_2",
dpars = c("mu", "mub", "muc"),
links = "identity",
type = "int",
vars = c("n_cat"),
specials = "categorical"
)
Next, we use the stanvar() function to define our custom probability mass function and the corresponding function that will allow us to return predictions, which we’ll just save as stan_lpmf_2. Other than the names, notice that the major change is how we have defined the prob[i] parameters.
stan_lpmf_2 <- stanvar(block = "functions",
scode = "
real cond_log_2_lpmf(int y, real mu, real mu_b, real mu_c, int n_cat) {
real p_mu = inv_logit(mu);
real p_mub = inv_logit(mu_b);
real p_muc = inv_logit(mu_c);
vector[n_cat] prob;
prob[1] = p_mub * p_mu;
prob[2] = (1 - p_mub) * p_mu;
prob[3] = p_muc * (1 - p_mu);
prob[4] = (1 - p_muc) * (1 - p_mu);
return(categorical_lpmf(y | prob));
}
vector cond_log_2_pred(int y, real mu, real mu_b, real mu_c, int n_cat) {
real p_mu = inv_logit(mu);
real p_mub = inv_logit(mu_b);
real p_muc = inv_logit(mu_c);
vector[n_cat] prob;
prob[1] = p_mub * p_mu;
prob[2] = (1 - p_mub) * p_mu;
prob[3] = p_muc * (1 - p_mu);
prob[4] = (1 - p_muc) * (1 - p_mu);
return(prob);
}
")
Now we’re ready to fit the model with brm(). Again, notice how our use of the family and stanvars functions.
fit22.4 <-
brm(data = d4,
family = cond_log_2,
Y ~ 1 + X1 + X2,
prior = c(prior(normal(0, 20), class = Intercept, dpar = mu2),
prior(normal(0, 20), class = Intercept, dpar = mu3),
prior(normal(0, 20), class = Intercept, dpar = mu4),
prior(normal(0, 20), class = b, dpar = mu2),
prior(normal(0, 20), class = b, dpar = mu3),
prior(normal(0, 20), class = b, dpar = mu4)),
iter = 2000, warmup = 1000, cores = 4, chains = 4,
seed = 22,
stanvars = stan_lpmf_2 + stanvars,
file = "fits/fit22.04")
Check the model summary.
print(fit22.4)
## Family: cond_log_2
## Links: mu2 = identity; mu3 = identity; mu4 = identity
## Formula: Y ~ 1 + X1 + X2
## Data: d4 (Number of observations: 475)
## Draws: 4 chains, each with iter = 2000; warmup = 1000; thin = 1;
## total post-warmup draws = 4000
##
## Population-Level Effects:
## Estimate Est.Error l-95% CI u-95% CI Rhat Bulk_ESS Tail_ESS
## mu2_Intercept -4.05 0.46 -5.02 -3.23 1.00 2757 2184
## mu3_Intercept -1.39 1.19 -3.80 0.87 1.00 2632 2185
## mu4_Intercept -1.02 0.23 -1.50 -0.60 1.00 2824 2668
## mu2_X1 -4.79 0.52 -5.90 -3.84 1.00 2769 2286
## mu2_X2 0.35 0.20 -0.04 0.74 1.00 4245 2441
## mu3_X1 1.54 0.88 -0.13 3.28 1.00 2668 2139
## mu3_X2 -5.36 1.16 -7.86 -3.39 1.00 3306 2241
## mu4_X1 3.03 0.38 2.34 3.81 1.00 1872 2428
## mu4_X2 3.13 0.36 2.49 3.86 1.00 2219 2511
##
## Draws were sampled using sampling(NUTS). For each parameter, Bulk_ESS
## and Tail_ESS are effective sample size measures, and Rhat is the potential
## scale reduction factor on split chains (at convergence, Rhat = 1).
We can use the same basic workflow as before to make our version of the upper half of Figure 22.7.
# extract the posterior draws
draws <- as_draws_df(fit22.4)
# 2D thresholds on the left
set.seed(22)
p1 <-
draws %>%
mutate(draw = 1:n()) %>%
slice_sample(n = 30) %>%
pivot_longer(starts_with("b_")) %>%
mutate(name = str_remove(name, "b_mu")) %>%
separate(name, into = c("lambda", "parameter")) %>%
pivot_wider(names_from = parameter, values_from = value) %>%
mutate(intercept = -Intercept / X2,
slope = -X1 / X2) %>%
ggplot() +
geom_text(data = d4,
aes(x = X1, y = X2, label = Y, color = factor(Y)),
size = 3, show.legend = F) +
geom_abline(aes(intercept = intercept,
slope = slope,
group = interaction(draw, lambda),
linetype = lambda),
linewidth = 1/4, alpha = 1/2) +
scale_color_viridis_d(option = "F", begin = .15, end = .85) +
scale_linetype(NULL,
labels = parse(text = c(
"lambda['{1,2}|{1,2,3,4}']",
"lambda['{1}|{1,2}']",
"lambda['{3}|{3,4}']")),
guide = guide_legend(
direction = "vertical",
label.hjust = 0.5,
label.theme = element_text(size = 10))) +
labs(x = expression(x[1]),
y = expression(x[2])) +
theme(legend.justification = 0.5,
legend.position = "top")
# marginal posteriors on the right
p2 <-
draws %>%
pivot_longer(-lp__) %>%
mutate(name = str_remove(name, "b_")) %>%
mutate(number = str_extract(name, "[2-4]+")) %>%
mutate(lambda = case_when(number == "2" ~ "lambda['{1,2}|{1,2,3,4}']",
number == "3" ~ "lambda['{1}|{1,2}']",
number == "4" ~ "lambda['{3}|{3,4}']"),
parameter = case_when(str_detect(name, "Intercept") ~ "beta[0]",
str_detect(name, "X1") ~ "beta[1]",
str_detect(name, "X2") ~ "beta[2]")) %>%
# plot
ggplot(aes(x = value, y = 0)) +
stat_histinterval(point_interval = mode_hdi, .width = .95, size = 1,
normalize = "panels") +
scale_y_continuous(NULL, breaks = NULL) +
xlab("marginal posterior") +
facet_grid(lambda ~ parameter, labeller = label_parsed, scales = "free_x")
# combine, entitle, and display the results
(p1 + p2) &
plot_layout(widths = c(1, 2)) &
plot_annotation(title = "Figure 22.7, upper half",
subtitle = "Results from the conditional logistic model fit to the d4 data via the custom-family approach")
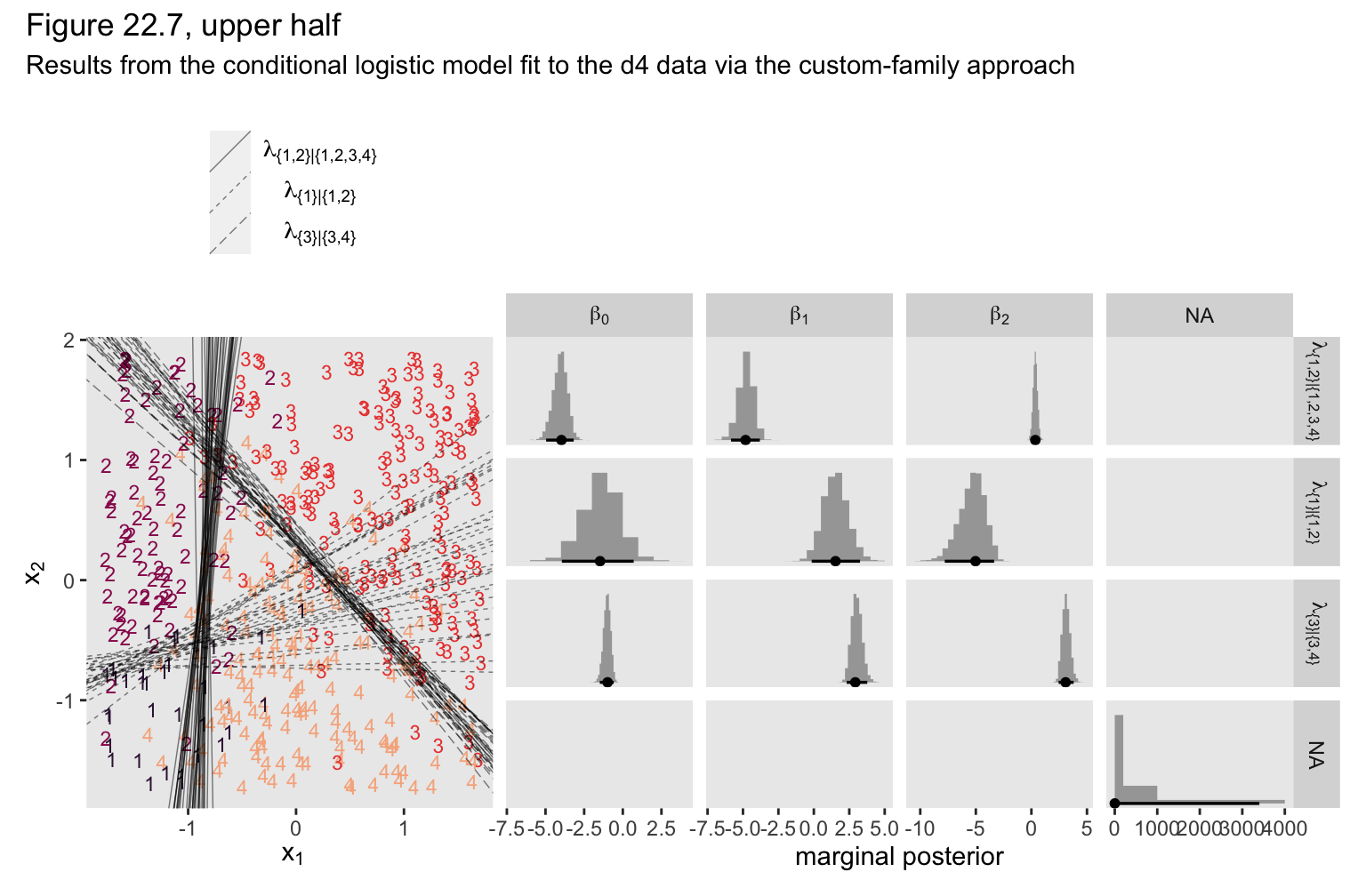
As Kruschke pointed out in the text,
notice that the estimates for
\(\lambda_2\)are more uncertain, with wider HDI’s, than the other coefficients. This uncertainty is also shown in the threshold lines on the data: The lines separating the 1’s from the 2’s have a much wider spread than the other boundaries. Inspection of the scatter plot explains why: There is only a small zone of data that informs the separation of 1’s from 2’s, and therefore the estimate must be relatively ambiguous. (p. 665)
I’m not going to go through a full demonstration like before, but if you want to use more brms post processing functions for fit22.4 or any other model fit with our custom cond_log_2 function, you’d need to execute this block of code first. Then post process to your heart’s desire.
expose_functions(fit22.4, vectorize = TRUE)
# for information criteria
log_lik_cond_log_2 <- function(i, prep) {
mu <- brms::get_dpar(prep, "mu2", i = i)
mub <- brms::get_dpar(prep, "mu3", i = i)
muc <- brms::get_dpar(prep, "mu4", i = i)
n_cat <- prep$data$n_cat
y <- prep$data$Y[i]
cond_log_2_lpmf(y, mu, mub, muc, n_cat)
}
# for conditional expectations
posterior_epred_cond_log_2 <- function(prep) {
mu <- brms::get_dpar(prep, "mu2")
mu_b <- brms::get_dpar(prep, "mu3")
mu_c <- brms::get_dpar(prep, "mu4")
n_cat <- prep$data$n_cat
y <- prep$data$Y
prob <- cond_log_2_pred(y = y, mu = mu, mu_b = mu_b, mu_c = mu_c, n_cat = n_cat)
dim(prob) <- c(dim(prob)[1], dim(mu))
prob <- aperm(prob, c(2,3,1))
dimnames(prob) <- list(
as.character(seq_len(dim(prob)[1])),
NULL,
as.character(seq_len(dim(prob)[3]))
)
prob
}
# for posterior predictions
posterior_predict_cond_log_2 <- function(i, prep, ...) {
mu <- brms::get_dpar(prep, "mu2", i = i)
mu_b <- brms::get_dpar(prep, "mu3", i = i)
mu_c <- brms::get_dpar(prep, "mu4", i = i)
n_cat <- prep$data$n_cat
y <- prep$data$Y[i]
prob <- cond_log_2_pred(y, mu, mu_b, mu_c, n_cat)
# make sure you have the extraDistr package
extraDistr::rcat(length(mu), t(prob))
}
In this section of the text, Kruschke also showed the results of when he analyzed the two data sets with the non-data-generating likelihoods. In the lower half of Figure 22.6, he showed the results of his second version of the conditional logistic model applied to the d3 data. In the lower half of Figure 22.7, he showed the results of his first version of the conditional logistic model applied to the d4 data. Since this section is already complicated enough, we’re not going to do that. But if you’d like to see what happens, consider it a personal homework assignment.
In principle, the different conditional logistic models could be put into an overarching hierarchical model comparison. If you have only a few specific candidate models to compare, this could be a feasible approach. But it is not an easily pursued approach to selecting a partition of outcomes from all possible partitions of outcomes when there are many outcomes… Therefore, it is typical to consider a single model, or small set of models, that are motivated by being meaningful in the context of the application, and interpreting the parameter estimates in that meaningful context. (p. 667)
Kruschke finished this section with:
Finally, when you run the models in JAGS, you may find that there is high autocorrelation in the MCMC chains (even with standardized data), which requires a very long chain for adequate ESS. This suggests that Stan might be a more efficient approach.
Since we fit our models with Stan via brms, high autocorrelations and low effective sample sizes weren’t a problem. For example, here are the bulk and tail effective sample sizes for both of our two models.
library(posterior)
bind_rows(
as_draws_df(fit22.3) %>% summarise_draws(),
as_draws_df(fit22.4) %>% summarise_draws()
) %>%
mutate(fit = rep(c("fit22.3", "fit22.4"), each = n() / 2)) %>%
pivot_longer(starts_with("ess")) %>%
ggplot(aes(x = value)) +
geom_histogram(binwidth = 250) +
xlim(0, NA) +
facet_grid(fit ~ name)
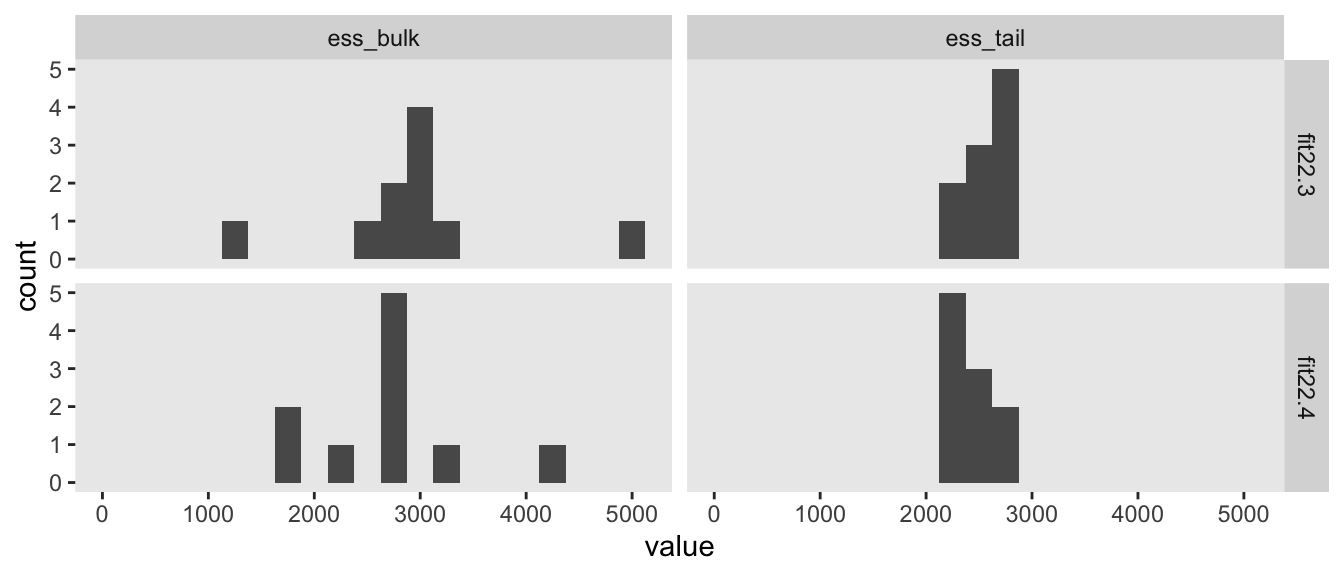
The values look pretty good. We may as well look at the autocorrelations. To keep things simple, this time we’ll restrict our analysis to fit22.4. [The results are largely the same for fit22.3.]
library(bayesplot)
ac <-
as_draws_df(fit22.4) %>%
mutate(chain = .chain) %>%
select(b_mu2_Intercept:b_mu4_X1, chain) %>%
mcmc_acf(lags = 5)
ac$data %>%
filter(Lag > 0) %>%
ggplot(aes(x = AC)) +
geom_vline(xintercept = 0, color = "white") +
geom_histogram(binwidth = 0.05) +
scale_x_continuous("autocorrelation", limits = c(-1, 1),
labels = c("-1", "-.5", "0", ".5", "1")) +
facet_grid(Lag ~ Chain, labeller = label_both)
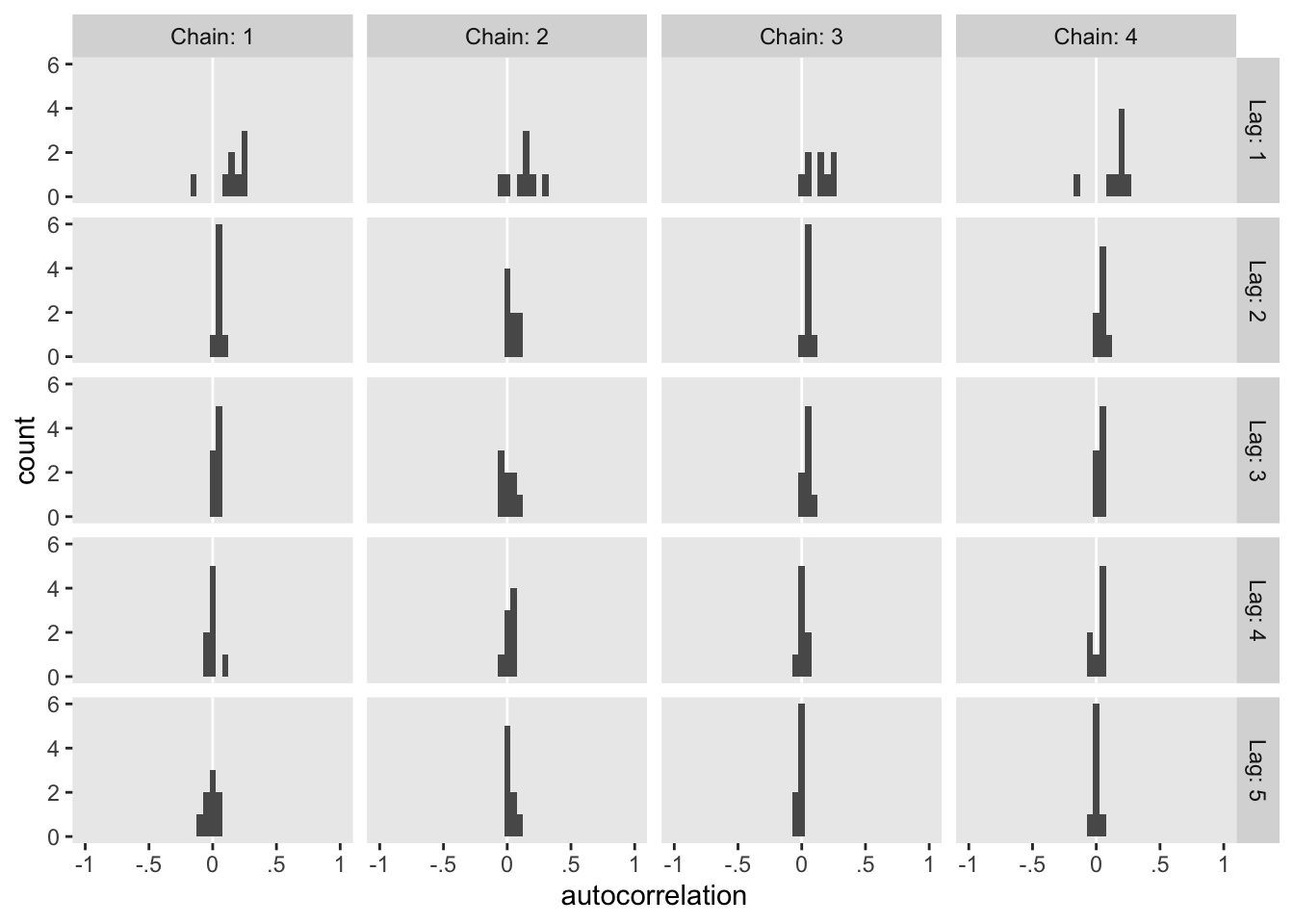
On the whole, the autocorrelations are reasonably low across all parameters, chains, and lags.
Conditional logistic models by sequential ordinal regression.
In their ( 2019) paper, Ordinal regression models in psychology: A tutorial, Bürkner and Vourre outlined a framework for fitting a variety of orginal models with brms. We’ll learn more about ordinal models in [Chapter 23][Ordinal Predicted Variable]. In this section, we’ll use Mattan Ben-Shachar’s strategy and purpose one of the ordinal models to fit a conditional logistic model to our nominal data.
As outlined in Bürkner & Vuorre (
2019), and as we will learn in greater detain in the next chapter, many ordinal regression models presume an underlying continuous process. However, you can use a sequential model in cases where one level of the criterion is only possible after the lower levels of the criterion have been achieved. Although this is not technically correct for the nominal variable Y in the d3 data set, the simple hierarchical sequence Kruschke used to model those data does follow that same pattern. Ben-Shachar’s insight was that if we treat our nominal variable Y as ordinal, the sequential model will mimic the sequential-ness of Kruschke’s binary-choices hierarchy. To get this to work, we first have to save an ordinal version of Y, which we’ll call Y_ord.
d3 <-
d3 %>%
mutate(Y_ord = ordered(Y))
# what are the new attributes?
attributes(d3$Y_ord)
## $levels
## [1] "1" "2" "3" "4"
##
## $class
## [1] "ordered" "factor"
Within brm() we fit sequential models using family = sratio, which defaults to the logit link. If you want to use predictors in a model of this kind and you would like those coefficients to vary across the different levels of the criterion, you need to insert the predictor terms within the cs() function. Here’s how to fit the model with brm().
fit22.5 <-
brm(data = d3,
family = sratio,
Y_ord ~ 1 + cs(X1) + cs(X2),
prior = c(prior(normal(0, 20), class = Intercept),
prior(normal(0, 20), class = b)),
iter = 2000, warmup = 1000, cores = 4, chains = 4,
seed = 22,
file = "fits/fit22.05")
Check the model summary.
print(fit22.5)
## Family: sratio
## Links: mu = logit; disc = identity
## Formula: Y_ord ~ 1 + cs(X1) + cs(X2)
## Data: d3 (Number of observations: 475)
## Draws: 4 chains, each with iter = 2000; warmup = 1000; thin = 1;
## total post-warmup draws = 4000
##
## Population-Level Effects:
## Estimate Est.Error l-95% CI u-95% CI Rhat Bulk_ESS Tail_ESS
## Intercept[1] -4.01 0.47 -4.97 -3.14 1.00 2850 2689
## Intercept[2] -2.12 0.35 -2.84 -1.48 1.00 2864 2875
## Intercept[3] -0.97 0.32 -1.61 -0.37 1.00 3162 3039
## X1[1] 4.92 0.54 3.93 6.04 1.00 2820 2570
## X1[2] -0.74 0.29 -1.30 -0.19 1.00 3511 3244
## X1[3] -3.00 0.50 -4.02 -2.10 1.00 3307 2966
## X2[1] -0.01 0.20 -0.38 0.38 1.00 4316 2519
## X2[2] 5.22 0.63 4.07 6.52 1.00 2837 2616
## X2[3] -3.11 0.53 -4.23 -2.14 1.00 2902 2640
##
## Family Specific Parameters:
## Estimate Est.Error l-95% CI u-95% CI Rhat Bulk_ESS Tail_ESS
## disc 1.00 0.00 1.00 1.00 NA NA NA
##
## Draws were sampled using sampling(NUTS). For each parameter, Bulk_ESS
## and Tail_ESS are effective sample size measures, and Rhat is the potential
## scale reduction factor on split chains (at convergence, Rhat = 1).
One thing that might not be apparent at first glance is that although this model is essentially equivalent to the family = cond_log_1 version of the model we fit with fit22.3, above, the parameters are a little different. The intercepts are largely the same. However, the coefficients for the X1 and X2 predictors have switched signs. This will be easier to see with a coefficient plot comparing fit22.3 and fit22.5.
rbind(fixef(fit22.3)[c(1:4, 6, 8, 5, 7, 9), ], fixef(fit22.5)) %>%
data.frame() %>%
mutate(beta = rep(str_c("beta[", c(0:2, 0:2), "]"), each = 3),
lambda = rep(str_c("lambda==", 1:3), times = 3 * 2),
family = rep(c("cond_log_1", "sratio"), each = 9)) %>%
# plot!
ggplot(aes(x = Estimate, xmin = Q2.5, xmax = Q97.5, y = family)) +
geom_vline(xintercept = 0, color = "white") +
geom_pointrange(linewidth = 1/2, fatten = 5/4) +
# stat_pointinterval(.width = .95, point_size = 1.5, size = 1) +
labs(x = "marginal posterior",
y = NULL) +
facet_grid(lambda ~ beta, labeller = label_parsed, scales = "free_x")
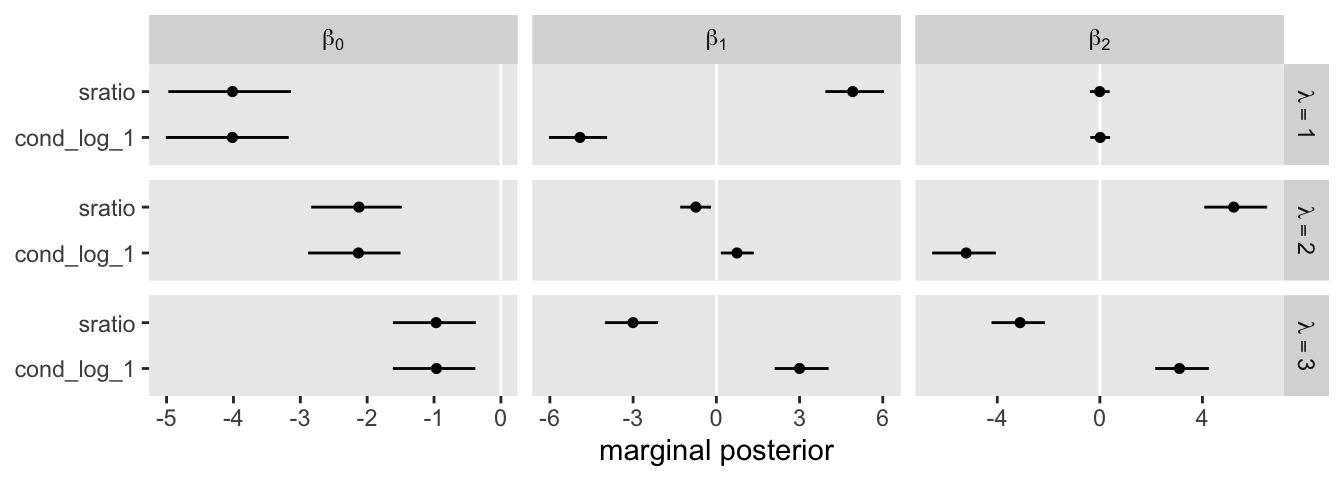
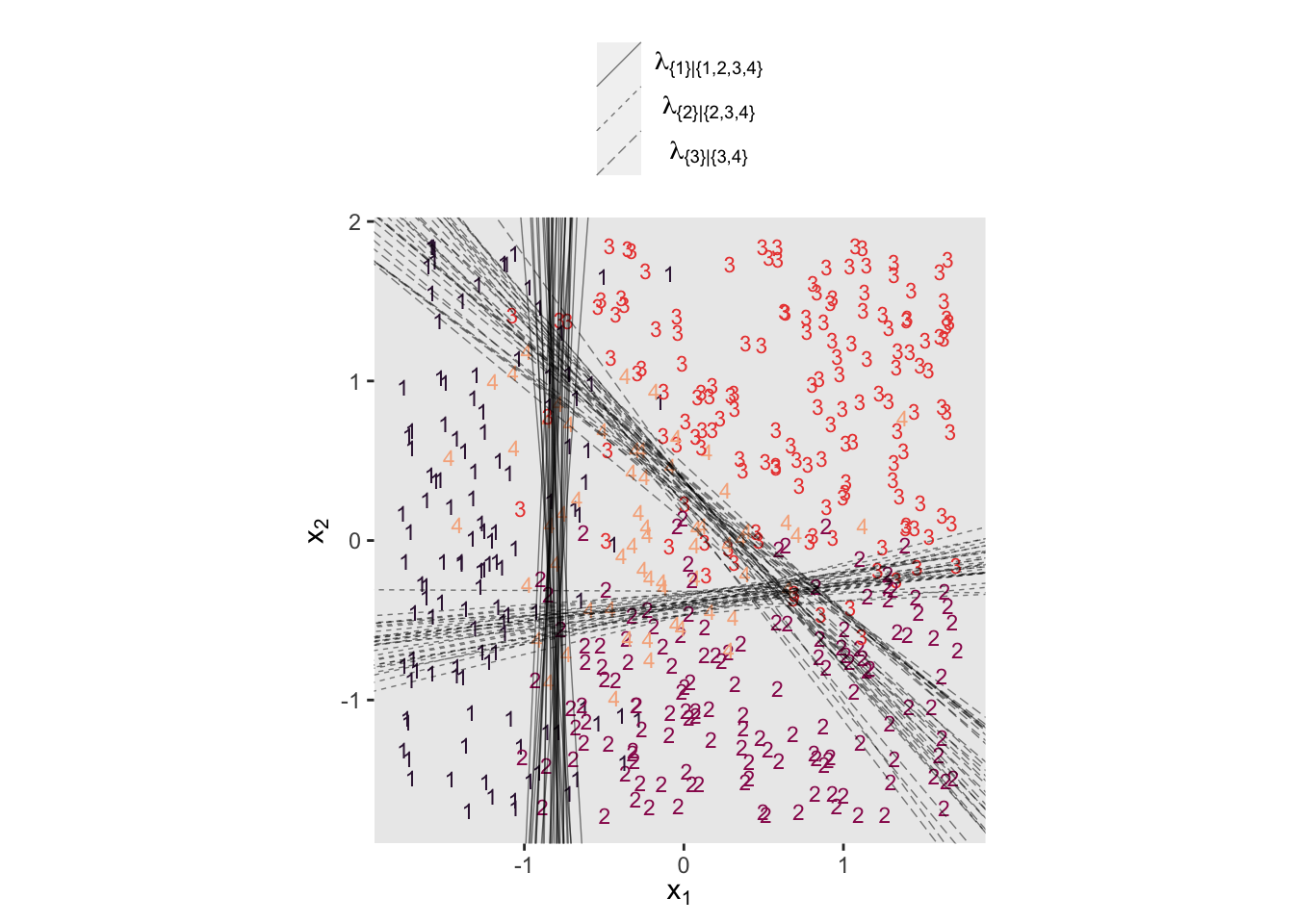
Even though the \(\beta_1\) and \(\beta_2\) parameters switched signs, their magnitudes are about the same. Thus, if we want to use our fit22.5 to plot the thresholds as in Figure 22.6, we’ll have to update our threshold formula to
$$x_2 = (\color{red}{+} \color{black}{\beta_0 / \beta_2) + (\beta_1 / \beta_2)x_1.}$$
With that adjustment in line, here’s our updated version of the left panel of Figure 22.6.
set.seed(22)
as_draws_df(fit22.5) %>%
slice_sample(n = 30) %>%
pivot_longer(starts_with("b")) %>%
mutate(name = str_remove(name, "b_") %>% str_remove(., "bcs_")) %>%
separate(name, into = c("parameter", "lambda")) %>%
pivot_wider(names_from = parameter, values_from = value) %>%
# this line is different
mutate(intercept = Intercept / X2,
slope = -X1 / X2) %>%
ggplot() +
geom_text(data = d3,
aes(x = X1, y = X2, label = Y, color = factor(Y)),
size = 3, show.legend = F) +
geom_abline(aes(intercept = intercept,
slope = slope,
group = interaction(.draw, lambda),
linetype = lambda),
linewidth = 1/4, alpha = 1/2) +
scale_color_viridis_d(option = "F", begin = .15, end = .85) +
scale_linetype(NULL,
labels = parse(text = c(
"lambda['{1}|{1,2,3,4}']",
"lambda['{2}|{2,3,4}']",
"lambda['{3}|{3,4}']")),
guide = guide_legend(
direction = "vertical",
label.hjust = 0.5,
label.theme = element_text(size = 10))) +
coord_equal() +
labs(x = expression(x[1]),
y = expression(x[2])) +
theme(legend.justification = 0.5,
legend.position = "top")
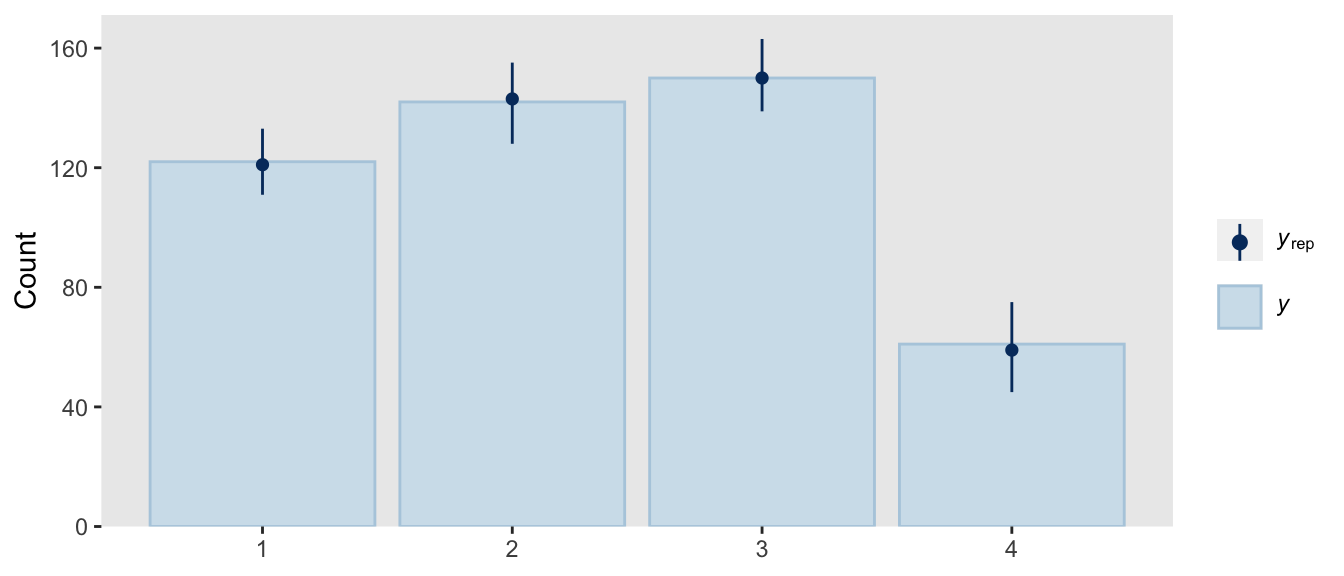
Though we used a different likelihood and a different formula for the thresholds, we got same basic model results. They’re just parameterized in a slightly different way. The nice thing with the family = sratio approach is all of the typical brms post processing functions will work out of the box. For example, here’s the posterior predictive check via pp_check().
pp_check(fit22.5,
type = "bars",
ndraws = 100,
size = 1/2,
fatten = 2)
Also note how the information criteria estimates for the two approaches are essentially the same.
fit22.5 <- add_criterion(fit22.5, criterion = "waic")
loo_compare(fit22.3, fit22.5, criterion = "waic") %>%
print(simplify = F)
## elpd_diff se_diff elpd_waic se_elpd_waic p_waic se_p_waic waic
## fit22.3 0.0 0.0 -230.8 16.8 9.3 1.1 461.6
## fit22.5 -0.1 0.1 -230.9 16.8 9.4 1.1 461.8
## se_waic
## fit22.3 33.6
## fit22.5 33.6
A limitation of the family = sratio method for conditional logistic models is it requires a simple binary-divisions hierarchy that resembles the one we just used, the one in the left panel of Figure 22.2. It is not well suited for the more complicated hierarchy displayed in the right panel of Figure 22.2, nor will it help you make sense of data generated by that kind of mechanism. For example, consider what happens when we try to use family = sratio with the d4 data.
# make an ordinal version of Y
d4 <-
d4 %>%
mutate(Y_ord = ordered(Y))
# fit the model
fit22.6 <-
brm(data = d4,
family = sratio,
Y_ord ~ 1 + cs(X1) + cs(X2),
prior = c(prior(normal(0, 20), class = Intercept),
prior(normal(0, 20), class = b)),
iter = 2000, warmup = 1000, cores = 4, chains = 4,
seed = 22,
file = "fits/fit22.06")
print(fit22.6)
## Family: sratio
## Links: mu = logit; disc = identity
## Formula: Y_ord ~ 1 + cs(X1) + cs(X2)
## Data: d4 (Number of observations: 475)
## Draws: 4 chains, each with iter = 2000; warmup = 1000; thin = 1;
## total post-warmup draws = 4000
##
## Population-Level Effects:
## Estimate Est.Error l-95% CI u-95% CI Rhat Bulk_ESS Tail_ESS
## Intercept[1] -6.03 0.76 -7.66 -4.67 1.00 2040 2169
## Intercept[2] -5.40 0.68 -6.85 -4.18 1.00 1757 2104
## Intercept[3] -1.02 0.24 -1.50 -0.59 1.00 2666 2522
## X1[1] 2.71 0.47 1.85 3.70 1.00 2251 2266
## X1[2] 5.56 0.70 4.30 7.04 1.00 1900 2424
## X1[3] -3.03 0.39 -3.84 -2.32 1.00 2565 2447
## X2[1] 2.38 0.43 1.60 3.26 1.00 2525 2449
## X2[2] -1.16 0.29 -1.75 -0.63 1.00 3524 2736
## X2[3] -3.13 0.37 -3.89 -2.46 1.00 2718 2738
##
## Family Specific Parameters:
## Estimate Est.Error l-95% CI u-95% CI Rhat Bulk_ESS Tail_ESS
## disc 1.00 0.00 1.00 1.00 NA NA NA
##
## Draws were sampled using sampling(NUTS). For each parameter, Bulk_ESS
## and Tail_ESS are effective sample size measures, and Rhat is the potential
## scale reduction factor on split chains (at convergence, Rhat = 1).
If you look at the parameter summary, nothing obviously bad happened. The computer didn’t crash or anything. To get a better sense of the damage, we plot.
# extract the posterior draws for fit22.6
draws <- as_draws_df(fit22.6)
# 2D thresholds on the left
set.seed(22)
p1 <-
draws %>%
slice_sample(n = 30) %>%
pivot_longer(starts_with("b")) %>%
mutate(name = str_remove(name, "b_") %>% str_remove(., "bcs_")) %>%
separate(name, into = c("parameter", "lambda")) %>%
pivot_wider(names_from = parameter, values_from = value) %>%
# still using the adjusted formula for the thresholds
mutate(intercept = Intercept / X2,
slope = -X1 / X2) %>%
ggplot() +
geom_text(data = d3,
aes(x = X1, y = X2, label = Y, color = factor(Y)),
size = 3, show.legend = F) +
geom_abline(aes(intercept = intercept,
slope = slope,
group = interaction(.draw, lambda),
linetype = lambda),
linewidth = 1/4, alpha = 1/2) +
scale_color_viridis_d(option = "F", begin = .15, end = .85) +
scale_linetype(NULL,
labels = parse(text = c(
"lambda['{1}|{1,2,3,4}']",
"lambda['{2}|{2,3,4}']",
"lambda['{3}|{3,4}']")),
guide = guide_legend(
direction = "vertical",
label.hjust = 0.5,
label.theme = element_text(size = 10))) +
labs(x = expression(x[1]),
y = expression(x[2])) +
theme(legend.justification = 0.5,
legend.position = "top")
# marginal posteriors on the right
p2 <-
draws %>%
pivot_longer(starts_with("b")) %>%
mutate(name = str_remove(name, "b_")%>% str_remove(., "bcs_")) %>%
separate(name, into = c("parameter", "lambda")) %>%
mutate(lambda = case_when(lambda == "1" ~ "lambda['{1}|{1,2,3,4}']",
lambda == "2" ~ "lambda['{2}|{2,3,4}']",
lambda == "3" ~ "lambda['{3}|{3,4}']"),
parameter = case_when(parameter == "Intercept" ~ "beta[0]",
parameter == "X1" ~ "beta[1]",
parameter == "X2" ~ "beta[2]")) %>%
# plot
ggplot(aes(x = value, y = 0)) +
stat_histinterval(point_interval = mode_hdi, .width = .95, size = 1,
normalize = "panels") +
scale_y_continuous(NULL, breaks = NULL) +
xlab("marginal posterior") +
facet_grid(lambda ~ parameter, labeller = label_parsed, scales = "free_x")
# combine, entitle, and display the results
(p1 + p2) &
plot_layout(widths = c(1, 2)) &
plot_annotation(title = "Figure 22.7, lower half",
subtitle = "Results from the conditional logistic model fit to the d4 data via the sequential-ordinal approach")
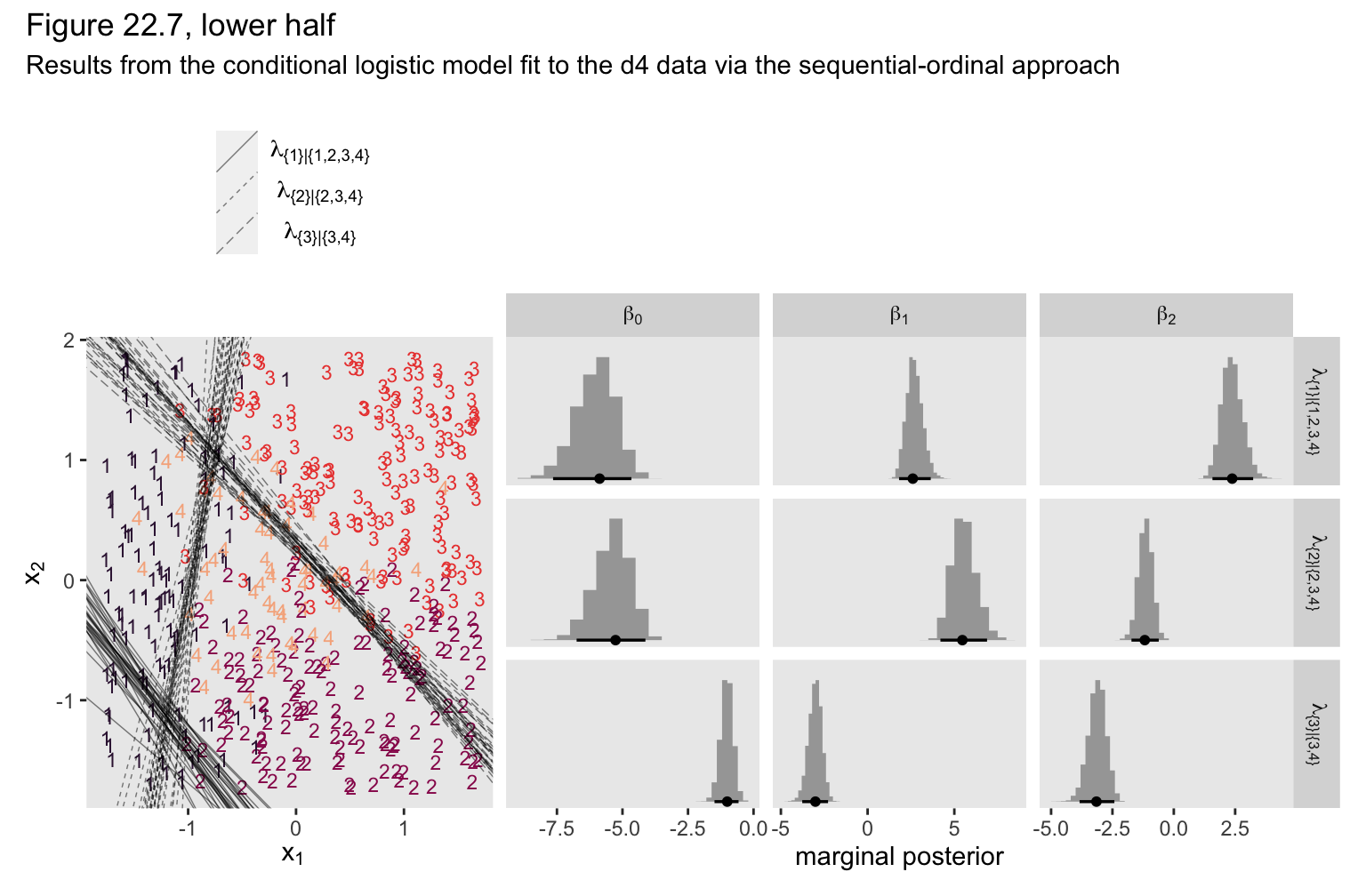
We ended up with our version of the lower half of Figure 22.7. As with the previous model, the sequential-ordinal approach reverses the signs for the \(\beta_1\) and \(\beta_2\) parameters, which isn’t a big deal as long as you keep that in mind. The larger issue is that the thresholds displayed in the left panel do a poor job differentiating among the various Y categories. The model underlying those thresholds is a bad match for the data.
Conditional logistic wrap-up.
To wrap this section up, we walked through approaches for fitting conditional logistic models with brms. First we considered Singmann’s method for using the brms custom family functionality to define bespoke likelihood functions. Though it requires a lot of custom coding and an above-average knowledge of the inner workings of brms and Stan, the custom family approach is very general and will possibly work for all your conditional-logistic needs. Then we considered Ben-Shachar sequential-ordinal approach. Ben-Shachar’s insight was that if we are willing to augment the nominal data with the ordered() function, modeling them with a sequential-ordinal model via family = sratio will return near equivalent results to the conditional logistic method. Though this method is attractive in that it uses a built-in likelihood and thus avoids a lot of custom coding, it is limited in that it will only handle nominal data which are well described by the simple binary-divisions hierarchy displayed in the left panel of Figure 22.2.
In closing, I would like to thank Singmann and Ben-Shachar for their time and insights. 🍻 I could not have finished this section without them. If you would like more examples of both of their methods applied to different data sets, check out the Stan forum thread called Nominal data and Kruschke’s “conditional logistic” approach.
Session info
sessionInfo()
## R version 4.2.0 (2022-04-22)
## Platform: x86_64-apple-darwin17.0 (64-bit)
## Running under: macOS Big Sur/Monterey 10.16
##
## Matrix products: default
## BLAS: /Library/Frameworks/R.framework/Versions/4.2/Resources/lib/libRblas.0.dylib
## LAPACK: /Library/Frameworks/R.framework/Versions/4.2/Resources/lib/libRlapack.dylib
##
## locale:
## [1] en_US.UTF-8/en_US.UTF-8/en_US.UTF-8/C/en_US.UTF-8/en_US.UTF-8
##
## attached base packages:
## [1] stats graphics grDevices utils datasets methods base
##
## other attached packages:
## [1] bayesplot_1.9.0 posterior_1.3.1 patchwork_1.1.2 tidybayes_3.0.2
## [5] brms_2.18.0 Rcpp_1.0.9 forcats_0.5.1 stringr_1.4.1
## [9] dplyr_1.0.10 purrr_0.3.4 readr_2.1.2 tidyr_1.2.1
## [13] tibble_3.1.8 ggplot2_3.4.0 tidyverse_1.3.2
##
## loaded via a namespace (and not attached):
## [1] readxl_1.4.1 backports_1.4.1 RcppEigen_0.3.3.9.3
## [4] plyr_1.8.7 igraph_1.3.4 svUnit_1.0.6
## [7] splines_4.2.0 crosstalk_1.2.0 TH.data_1.1-1
## [10] rstantools_2.2.0 inline_0.3.19 digest_0.6.30
## [13] htmltools_0.5.3 fansi_1.0.3 BH_1.78.0-0
## [16] magrittr_2.0.3 checkmate_2.1.0 googlesheets4_1.0.1
## [19] tzdb_0.3.0 modelr_0.1.8 RcppParallel_5.1.5
## [22] matrixStats_0.62.0 vroom_1.5.7 xts_0.12.1
## [25] sandwich_3.0-2 prettyunits_1.1.1 colorspace_2.0-3
## [28] rvest_1.0.2 ggdist_3.2.0 haven_2.5.1
## [31] xfun_0.35 callr_3.7.3 crayon_1.5.2
## [34] jsonlite_1.8.3 lme4_1.1-31 survival_3.4-0
## [37] zoo_1.8-10 glue_1.6.2 gtable_0.3.1
## [40] gargle_1.2.0 emmeans_1.8.0 distributional_0.3.1
## [43] pkgbuild_1.3.1 rstan_2.21.7 abind_1.4-5
## [46] scales_1.2.1 mvtnorm_1.1-3 emo_0.0.0.9000
## [49] DBI_1.1.3 miniUI_0.1.1.1 viridisLite_0.4.1
## [52] xtable_1.8-4 HDInterval_0.2.2 diffobj_0.3.5
## [55] bit_4.0.4 stats4_4.2.0 StanHeaders_2.21.0-7
## [58] DT_0.24 htmlwidgets_1.5.4 httr_1.4.4
## [61] threejs_0.3.3 arrayhelpers_1.1-0 ellipsis_0.3.2
## [64] pkgconfig_2.0.3 loo_2.5.1 farver_2.1.1
## [67] sass_0.4.2 dbplyr_2.2.1 utf8_1.2.2
## [70] labeling_0.4.2 tidyselect_1.1.2 rlang_1.0.6
## [73] reshape2_1.4.4 later_1.3.0 munsell_0.5.0
## [76] cellranger_1.1.0 tools_4.2.0 cachem_1.0.6
## [79] cli_3.4.1 generics_0.1.3 broom_1.0.1
## [82] ggridges_0.5.3 evaluate_0.18 fastmap_1.1.0
## [85] yaml_2.3.5 bit64_4.0.5 processx_3.8.0
## [88] knitr_1.40 fs_1.5.2 nlme_3.1-159
## [91] mime_0.12 projpred_2.2.1 xml2_1.3.3
## [94] compiler_4.2.0 shinythemes_1.2.0 rstudioapi_0.13
## [97] gamm4_0.2-6 reprex_2.0.2 bslib_0.4.0
## [100] stringi_1.7.8 highr_0.9 ps_1.7.2
## [103] blogdown_1.15 Brobdingnag_1.2-8 lattice_0.20-45
## [106] Matrix_1.4-1 nloptr_2.0.3 markdown_1.1
## [109] shinyjs_2.1.0 tensorA_0.36.2 vctrs_0.5.0
## [112] pillar_1.8.1 lifecycle_1.0.3 jquerylib_0.1.4
## [115] bridgesampling_1.1-2 estimability_1.4.1 httpuv_1.6.5
## [118] extraDistr_1.9.1 R6_2.5.1 bookdown_0.28
## [121] promises_1.2.0.1 gridExtra_2.3 codetools_0.2-18
## [124] boot_1.3-28 colourpicker_1.1.1 MASS_7.3-58.1
## [127] gtools_3.9.3 assertthat_0.2.1 withr_2.5.0
## [130] shinystan_2.6.0 multcomp_1.4-20 mgcv_1.8-40
## [133] parallel_4.2.0 hms_1.1.1 grid_4.2.0
## [136] minqa_1.2.5 coda_0.19-4 rmarkdown_2.16
## [139] googledrive_2.0.0 shiny_1.7.2 lubridate_1.8.0
## [142] base64enc_0.1-3 dygraphs_1.1.1.6
References
Bürkner, P.-C. (2021). Define custom response distributions with brms. https://CRAN.R-project.org/package=brms/vignettes/brms_customfamilies.html
Bürkner, P.-C., & Vuorre, M. (2019). Ordinal regression models in psychology: A tutorial. Advances in Methods and Practices in Psychological Science, 2(1), 77–101. https://doi.org/10.1177/2515245918823199
Kruschke, J. K. (2015). Doing Bayesian data analysis: A tutorial with R, JAGS, and Stan. Academic Press. https://sites.google.com/site/doingbayesiandataanalysis/
- Posted on:
- November 17, 2021
- Length:
- 43 minute read, 8995 words